【YOLOv8】YOLOv8改进系列(3)----替换主干网络之ConvNeXt V2

主页:HABUO🍁主页:HABUO
🍁YOLOv8入门+改进专栏🍁
🍁如果再也不能见到你,祝你早安,午安,晚安🍁
【YOLOv8改进系列】:
【YOLOv8】YOLOv8结构解读
YOLOv8改进系列(1)----替换主干网络之EfficientViT
YOLOv8改进系列(2)----替换主干网络之FasterNet
YOLOv8改进系列(3)----替换主干网络之ConvNeXt V2
YOLOv8改进系列(4)----替换C2f之FasterNet中的FasterBlock替换C2f中的Bottleneck
YOLOv8改进系列(5)----替换主干网络之EfficientFormerV2
YOLOv8改进系列(6)----替换主干网络之VanillaNet
YOLOv8改进系列(7)----替换主干网络之LSKNet
YOLOv8改进系列(8)----替换主干网络之Swin Transformer
YOLOv8改进系列(9)----替换主干网络之RepViT
目录
💯一、ConvNeXt V2介绍
1. 简介
2. ConvNeXt V2架构
2.1 全卷积掩码自编码器(FCMAE)
2.2 全局响应归一化(GRN)
3. 实验结果
3.1 ImageNet分类
3.2 COCO目标检测和分割
3.3 ADE20K语义分割
4. 关键结论
💯二、具体添加方法
第①步:创建convnextv2.py
第②步:修改task.py
(1)引入创建的convnextv2文件
(2)修改_predict_once函数
(3)修改parse_model函数
第③步:yolov8.yaml文件修改
第④步:验证是否加入成功
💯一、ConvNeXt V2介绍
- 论文题目:《ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders》
- 论文地址:2301.00808
1. 简介
论文提出了一个全卷积掩码自编码器框架和一个新的全局响应归一化(Global Response Normalization, GRN)层,用于增强 ConvNeXt 架构中通道间的特征竞争。这种自监督学习技术和架构改进的结合,形成了新的模型家族 ConvNeXt V2。
2. ConvNeXt V2架构
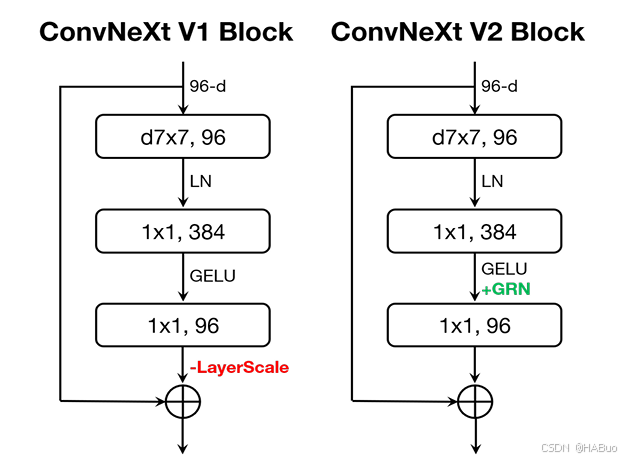
ConvNeXt V2 是在 ConvNeXt V1 的基础上改进而来,主要引入了以下两个关键创新:
2.1 全卷积掩码自编码器(FCMAE)
FCMAE 是一种全卷积的自监督学习框架,用于预训练 ConvNeXt V2 模型。其核心思想是随机掩盖输入图像的一部分,并让模型根据剩余的上下文预测被掩盖的部分。FCMAE 的主要组件包括:
-
掩码策略:随机掩盖输入图像的60%。
-
编码器设计:使用 ConvNeXt 模型作为编码器,并引入稀疏卷积(sparse convolution)来处理被掩盖的图像,防止信息从被掩盖区域泄露。
-
解码器设计:使用轻量级的 ConvNeXt 块作为解码器,简化了整体架构。
-
重建目标:计算重建图像与目标图像之间的均方误差(MSE),仅在被掩盖的区域计算损失。
2.2 全局响应归一化(GRN)
GRN 是一种新的归一化层,旨在增强通道间的特征竞争,解决 ConvNeXt V1 在掩码自编码器预训练时出现的特征坍塌问题。GRN 的工作流程包括:
-
全局特征聚合:通过全局函数聚合特征图。
-
特征归一化:对聚合后的特征进行归一化处理。
-
特征校准:将归一化后的特征重新校准到原始输入中。
GRN 的引入显著提高了模型在掩码自编码器预训练下的性能,且无需额外的参数开销。
3. 实验结果
论文通过一系列实验验证了 ConvNeXt V2 的性能提升,主要体现在以下几个方面:
3.1 ImageNet分类
ConvNeXt V2 在 ImageNet 分类任务上表现出色,尤其是在使用 FCMAE 预训练后,性能提升显著。例如:
-
Atto模型(3.7M 参数)在 ImageNet 上达到了 76.7% 的 top-1 准确率。
-
Huge模型(650M 参数)达到了 88.9% 的 top-1 准确率,刷新了使用公开数据的最高记录。
3.2 COCO目标检测和分割
在 COCO 数据集上,使用 Mask R-CNN 进行微调时,ConvNeXt V2 的性能优于 ConvNeXt V1 和其他基于 Swin Transformer 的模型。例如:
-
Base模型的 AP box 提升到 52.9%,AP mask 提升到 70.0%。
-
Huge模型的 AP box 提升到 55.7%,AP mask 提升到 72.8%。
3.3 ADE20K语义分割
在 ADE20K 数据集上,使用 UperNet 进行微调时,ConvNeXt V2 的性能也优于 ConvNeXt V1 和其他基于 Swin Transformer 的模型。例如:
-
Base模型的 mIoU 提升到 52.1%。
-
Huge模型的 mIoU 提升到 55.0%。
4. 关键结论
-
架构与学习框架的协同设计:通过重新设计 ConvNeXt 架构和自监督学习框架,ConvNeXt V2 在多种视觉任务上表现出色,证明了架构与学习框架协同设计的重要性。
-
掩码自编码器的有效性:FCMAE 框架使得 ConvNeXt V2 能够从掩码自编码器预训练中受益,显著提升了性能。
-
GRN层的作用:GRN 层通过增强特征多样性,解决了 ConvNeXt V1 在掩码自编码器预训练时的特征坍塌问题,是 ConvNeXt V2 性能提升的关键。
💯二、具体添加方法
第①步:创建convnextv2.py
创建完成后,将下面代码直接复制粘贴进去:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from timm.models.layers import trunc_normal_, DropPath
__all__ = ['convnextv2_atto', 'convnextv2_femto', 'convnextv2_pico', 'convnextv2_nano', 'convnextv2_tiny', 'convnextv2_base', 'convnextv2_large', 'convnextv2_huge']
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
""" GRN (Global Response Normalization) layer
"""
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class Block(nn.Module):
""" ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class ConvNeXtV2(nn.Module):
""" ConvNeXt V2
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
res = []
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
res.append(x)
return res
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def convnextv2_atto(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_femto(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_pico(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_nano(weights='', **kwargs):
model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_tiny(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_base(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_large(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model
def convnextv2_huge(weights='', **kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], **kwargs)
if weights:
model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))
return model第②步:修改task.py
(1)引入创建的convnextv2文件

from ultralytics.nn.backbone.convnextv2 import *(2)修改_predict_once函数
可直接将下述代码替换对应位置
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
for idx, m in enumerate(self.model):
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x if x_ is not None])}')
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
# if type(x) in {list, tuple}:
# if idx == (len(self.model) - 1):
# if type(x[1]) is dict:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x[1]["one2one"]])}')
# else:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x[1]])}')
# else:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x if x_ is not None])}')
# elif type(x) is dict:
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{", ".join([str(x_.size()) for x_ in x["one2one"]])}')
# else:
# if not hasattr(m, 'backbone'):
# print(f'layer id:{idx:>2} {m.type:>50} output shape:{x.size()}')
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x(3)修改parse_model函数
可以直接把下面的代码粘贴到对应的位置中
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""
Parse a YOLO model.yaml dictionary into a PyTorch model.
Args:
d (dict): Model dictionary.
ch (int): Input channels.
verbose (bool): Whether to print model details.
Returns:
(tuple): Tuple containing the PyTorch model and sorted list of output layers.
"""
import ast
# Args
max_channels = float("inf")
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
if len(scales[scale]) == 3:
depth, width, max_channels = scales[scale]
elif len(scales[scale]) == 4:
depth, width, max_channels, threshold = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"
{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<60}{'arguments':<50}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
is_backbone = False
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
try:
if m == 'node_mode':
m = d[m]
if len(args) > 0:
if args[0] == 'head_channel':
args[0] = int(d[args[0]])
t = m
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
except:
pass
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
try:
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
except:
args[j] = a
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in {
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, ELAN1, AConv, SPPELAN, C2fAttn, C3, C3TR,
C3Ghost, nn.Conv2d, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, PSA, SCDown, C2fCIB
}:
if args[0] == 'head_channel':
args[0] = d[args[0]]
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
elif m in {AIFI}:
args = [ch[f], *args]
c2 = args[0]
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
cm = make_divisible(min(cm, max_channels) * width, 8)
args = [c1, cm, c2, *args[2:]]
if m in (HGBlock):
args.insert(4, n) # number of repeats
n = 1
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in frozenset({Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn, v10Detect}):
args.append([ch[x] for x in f])
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
elif m is CBLinear:
c2 = make_divisible(min(args[0][-1], max_channels) * width, 8)
c1 = ch[f]
args = [c1, [make_divisible(min(c2_, max_channels) * width, 8) for c2_ in args[0]], *args[1:]]
elif m is CBFuse:
c2 = ch[f[-1]]
elif isinstance(m, str):
t = m
if len(args) == 2:
m = timm.create_model(m, pretrained=args[0], pretrained_cfg_overlay={'file': args[1]},
features_only=True)
elif len(args) == 1:
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
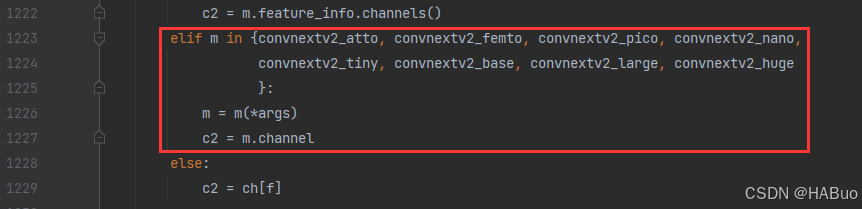
elif m in {convnextv2_atto, convnextv2_femto, convnextv2_pico, convnextv2_nano,
convnextv2_tiny, convnextv2_base, convnextv2_large, convnextv2_huge
}:
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
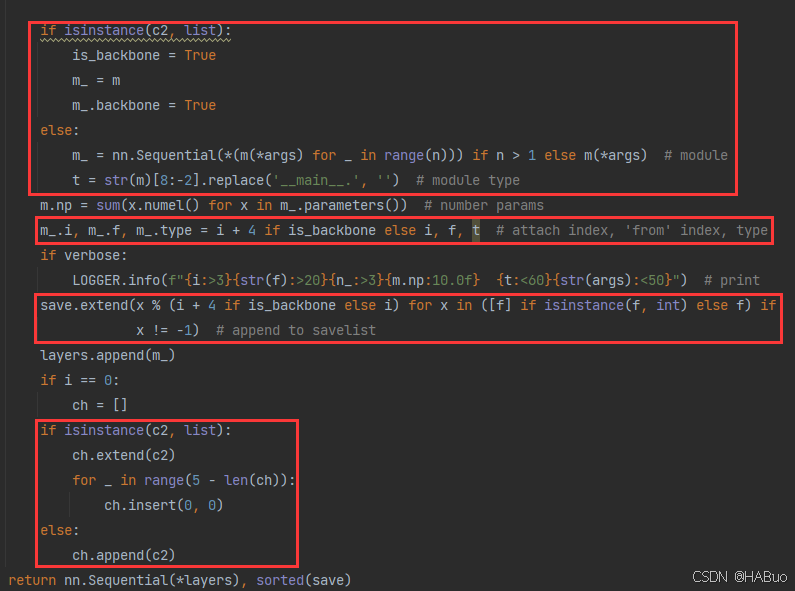
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if is_backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<60}{str(args):<50}") # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if
x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
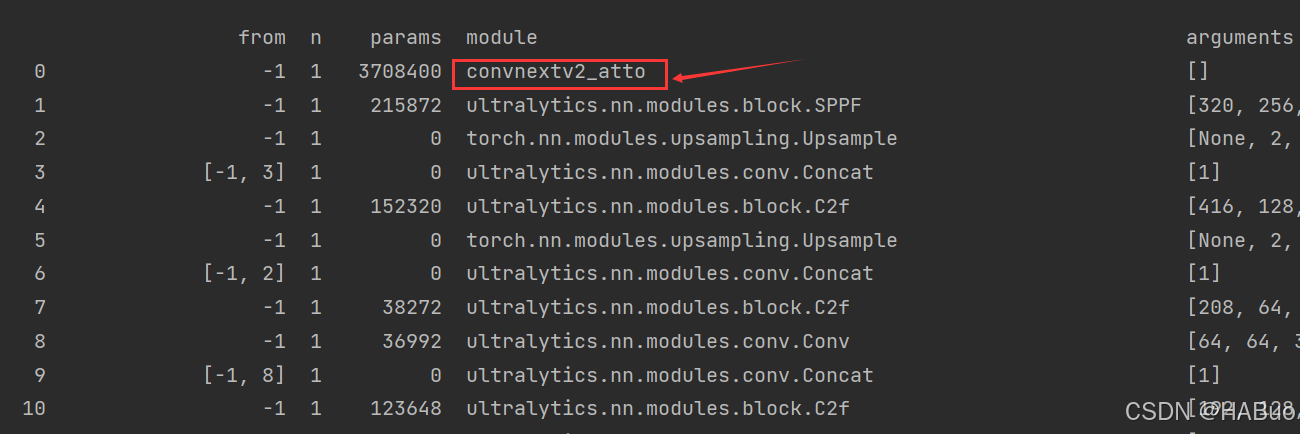
return nn.Sequential(*layers), sorted(save)具体改进差别如下图所示:
第③步:yolov8.yaml文件修改
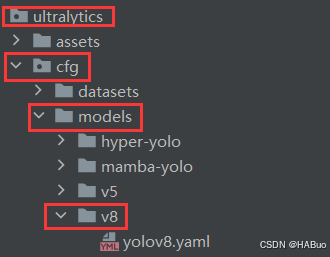
在下述文件夹中创立yolov8-convnextv2.yaml
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, convnextv2_atto, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
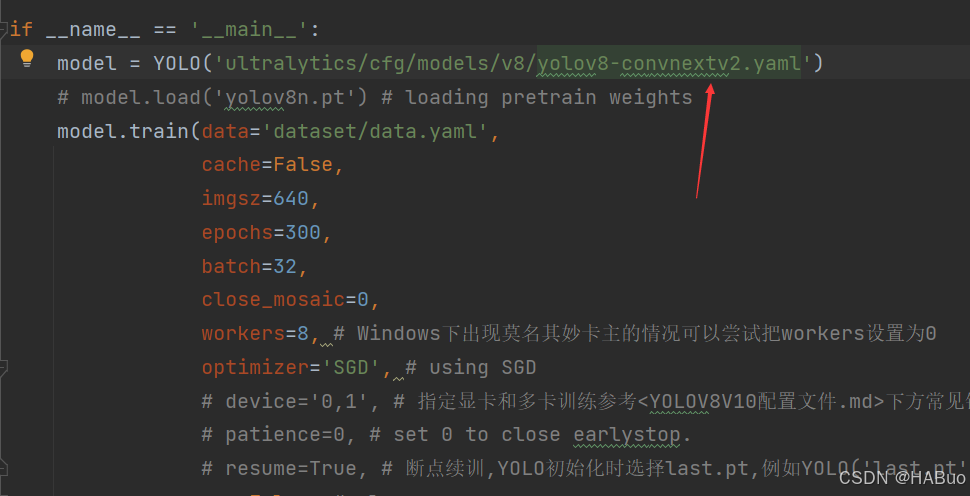
第④步:验证是否加入成功
将train.py中的配置文件进行修改,并运行
🏋不是每一粒种子都能开花,但播下种子就比荒芜的旷野强百倍🏋
🍁YOLOv8入门+改进专栏🍁
【YOLOv8改进系列】:
【YOLOv8】YOLOv8结构解读
YOLOv8改进系列(1)----替换主干网络之EfficientViT
YOLOv8改进系列(2)----替换主干网络之FasterNet
YOLOv8改进系列(3)----替换主干网络之ConvNeXt V2
YOLOv8改进系列(4)----替换C2f之FasterNet中的FasterBlock替换C2f中的Bottleneck
YOLOv8改进系列(5)----替换主干网络之EfficientFormerV2
YOLOv8改进系列(6)----替换主干网络之VanillaNet
YOLOv8改进系列(7)----替换主干网络之LSKNet
YOLOv8改进系列(8)----替换主干网络之Swin Transformer
YOLOv8改进系列(9)----替换主干网络之RepViT