增量预训练网络安全大模型的一次尝试
一、背景
探索使用网络安全知识,对开源基模型进行增强,评估是否能使基模型在网络安全领域表现出更好地专业度。
项目基于云起无垠SecGPT开源项目,在hugeface开源数据集的基础上,增加了自有预训练数据,进行增量预训练。
参考链接:
https://github.com/Clouditera/secgpt
二、数据集准备
0x1:预训练数据
预训练使用“安全书籍,安全知识库,安全论文,安全社区文章,漏洞库”等等安全内容,
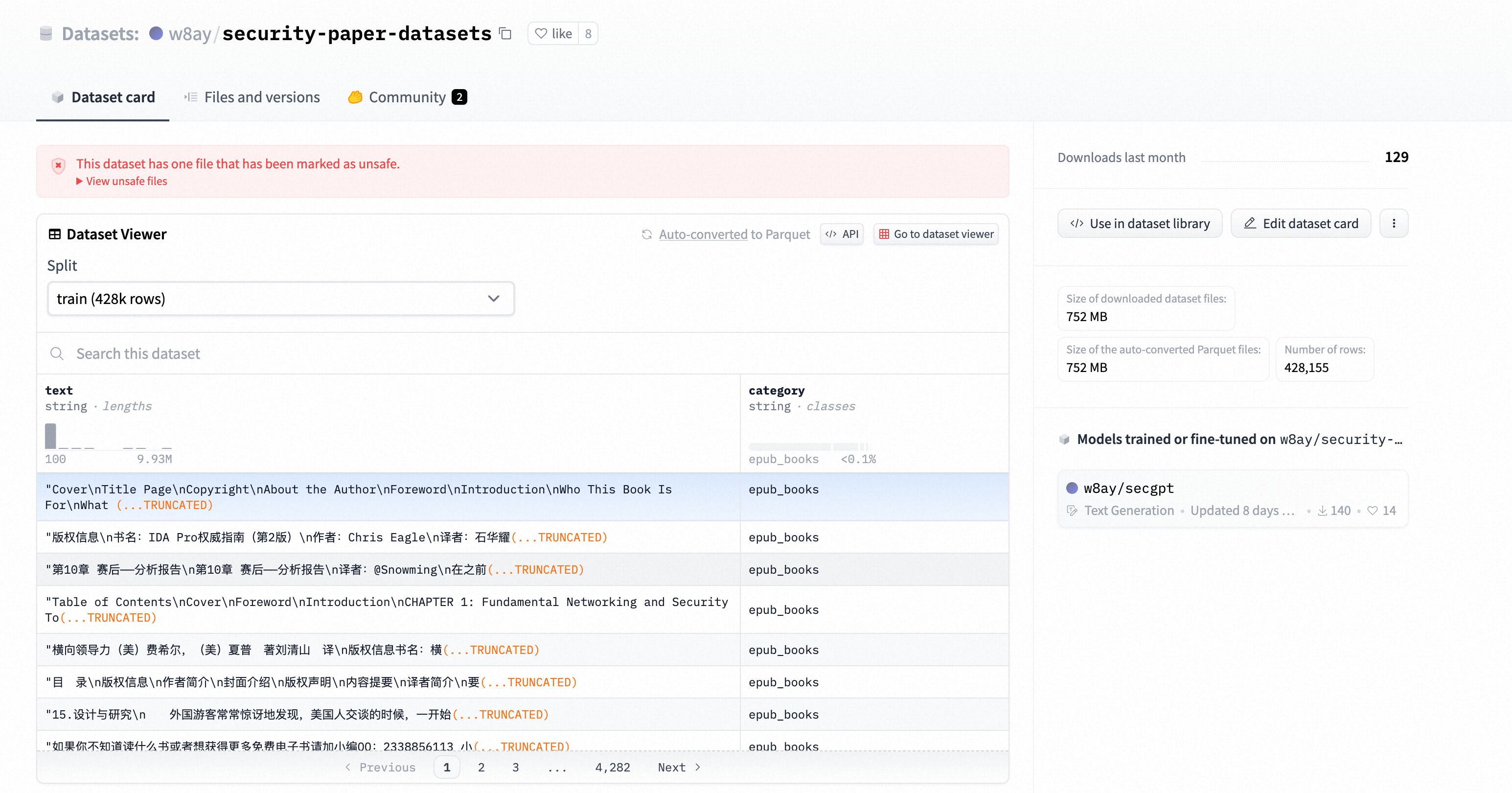
https://huggingface.co/datasets/w8ay/security-paper-datasets?row=0
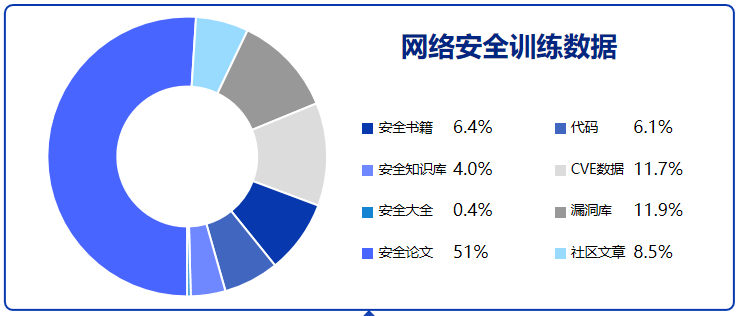
笔者增加了一份自己近10年以内的博客文章,

将上述格式转换为hugeface兼容格式,huggingface支持以下4种数据格式的数据集,只需要在load的时候设定格式就好了。
| Data format | Loading script | Example |
| CSV & TSV | csv | load_dataset("csv", data_files="my_file.csv") |
| Text files | text | load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines | json | load_dataset("json", data_files="my_file.jsonl") |