兄弟们,不会服务器繁忙的DeepSeek R1/V3真满血版来了,支持网页版和API接入,免费500万tokens吃到饱,绝绝子!!!
本文介绍了如何使用蓝耘元生代智算云平台的DeepSeek满血版服务,包括网页版访问和API接入方式。DeepSeek是一款强大的语言模型,支持文本生成、问答等多种任务。用户可通过蓝耘平台的网页版直接使用,避免服务器繁忙问题。此外,文章还详细介绍了如何将DeepSeek接入Chatbox,实现智能化聊天机器人。具体步骤包括创建API KEY、安装Chatbox、配置自定义提供方,并验证功能。蓝耘平台还提供累计1000万免费tokens(R1和V3各500W)供用户使用。
🧑 博主简介:现任阿里巴巴嵌入式技术专家,15年工作经验,深耕嵌入式+人工智能领域,精通嵌入式领域开发、技术管理、简历招聘面试。CSDN优质创作者,提供产品测评、学习辅导、简历面试辅导、毕设辅导、项目开发、C/C++/Java/Python/Linux/AI等方面的服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:
gylzbk)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

兄弟们,不会服务器繁忙的DeepSeek R1/V3真满血版来了,支持网页版和API接入,免费500万tokens吃到饱,绝绝子!!!
- 1. 什么是DeepSeek?
- 2. 网页版访问不会服务器繁忙的DeepSeek
- 2.1 使用说明
- 2.2 功能实测
- 3. Chatbox接入API
- 3.1 创建API KEY
- 3.2 下载安装Chatbox
- 3.3 配置DeepSeek
- 3.4 功能实测
- 3.5 注意事项
- 4. 总结
1. 什么是DeepSeek?
DeepSeek是一款基于深度学习的语言模型,具备强大的自然语言处理能力。它可以完成文本生成、问答、代码编写等多种任务,广泛应用于客服系统、内容创作、数据分析等领域。
在上一篇文章中,给大家介绍了《如何在蓝耘算力平台上快速部署DeepSeek》,但是受限于服务器成本,自己部署最多只能支持到32b,虽然也能覆盖大多数场景,但离满血版来说,还是会有一定的差距。所以,今天这篇文章给大家重点推荐一个已经部署好的真满血版DeepSeek,并且支持API调用,完全可以平替掉官方DeepSeek,给大家一个更好的选择。
2. 网页版访问不会服务器繁忙的DeepSeek
2.1 使用说明
如果需要直接网页端访问,直接访问蓝耘元生代智算云平台,注册并登录后就可以可以了。延迟低,速度快。
2.2 功能实测
我让它给我生成一篇题为模型压缩与量化:让大模型走向轻量化落地的技术博客。

它给我生成的内容如下:
# 一、引言
随着深度学习技术的快速发展,大型神经网络模型(如BERT、GPT-3等)在自然语言处理、计算机视觉等领域取得了令人瞩目的成就。然而,这些大模型通常需要大量的计算资源和存储空间,限制了它们在实际场景中的广泛应用。尤其是在移动设备、嵌入式系统等资源受限的环境中,直接部署大型模型变得异常困难。
为了克服这一问题,模型压缩与量化技术应运而生。通过模型压缩与量化,我们可以在保持模型性能的同时,显著降低模型的计算复杂度和存储需求,从而实现大模型在边缘设备上的高效部署。本文将详细介绍模型压缩与量化的基础概念、关键技术路径以及实际应用场景,并探讨这一领域的未来发展方向。
# 二、模型压缩与量化的基础知识
## 1. 什么是模型压缩?
模型压缩的目标是通过减少模型的参数数量或优化模型结构,降低模型的复杂度和计算需求。常见的压缩技术包括:
- 剪枝(Pruning):移除对模型贡献较小的神经元或权重。
- 蒸馏(Distillation):将大模型的知识迁移到一个更小、更轻量化的模型中。
## 2. 量化的基本原理
量化是通过降低数值精度来减少模型的存储和计算开销。例如,传统的浮点数运算使用32位浮点数(FP32),而量化技术可以将这些参数压缩到8位整数(INT8)或更低精度。
- 定点量化:将权重和激活值转换为低精度表示。
- 动态量化 vs 静态量化:动态量化在推理过程中实时调整缩放因子,静态量化则在训练后固定缩放因子。
- 量化感知训练(QAT):在训练阶段引入量化操作,提升量化模型的性能。
## 3. 量化 vs 压缩:区别与联系
压缩技术主要关注减少参数数量,而量化技术则是通过降低精度来优化计算效率。两者可以结合使用,以实现更高效的模型部署。
# 三、模型压缩与量化的关键技术路径
## 1. 模型剪枝(Network Pruning)
剪枝是一种直接减少模型参数数量的方法。根据剪枝策略的不同,可分为以下两类:
- 结构化剪枝:移除整个神经元或通道(如Channel Pruning),保证剪枝后的模型仍具有规则的网络结构。
- 非结构化剪肢:随机移除部分权重,可能会导致不规则的稀疏矩阵。
以下是一个简单的通道剪枝实现示例(使用Keras):
import tensorflow as tf from tensorflow.keras import layers, models # 加载预训练模型 model = models.VGG16(weights='imagenet', include_top=False) # 添加全连接层 flatten_layer = layers.Flatten() dense_layer1 = layers.Dense(4096, activation='relu') dense_layer2 = layers.Dense(4096, activation='relu') predictions = layers.Dense(1000, activation='softmax') model = models.Sequential([ model, flatten_layer, dense_layer1, dense_layer2, predictions ]) # 剪枝函数(通道剪枝) def prune_channels(model): # 遍历层,找到卷积层并剪枝 for layer in model.layers: if isinstance(layer, layers.Conv2D): # 获取权重和掩码 weights = layer.get_weights()[0] mask = tf.abs(weights) < 1e-3 # 剪枝阈值 # 更新权重 pruned_weights = weights * (1 - mask) layer.set_weights([pruned_weights] + layer.get_weights()[1:]) return model # 应用剪枝 pruned_model = prune_channels(model) # 重新编译模型并训练 pruned_model.compile( optimizer='adam', loss=tf.keras.losses.CategoricalCrossentropy(), metrics=['accuracy'] ) pruned_model.fit(train_dataset, epochs=10)## 2. 知识蒸馏(Knowledge Distillation)
知识蒸馏的核心思想是将大模型的知识迁移到一个更小的学生模型中。具体步骤如下:
- 使用大模型(教师模型)对数据进行训练。
- 将学生模型在教师模型的指导下进行微调,使其模仿教师模型的输出。
以下是一个简单的知识蒸馏实现示例(使用PyTorch):
import torch import torch.nn as nn from torch.utils.data import DataLoader # 教师模型(复杂模型) class TeacherModel(nn.Module): def __init__(self): super(TeacherModel, self).__init__() self.layers = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3), nn.ReLU(), nn.Conv2d(64, 128, kernel_size=3), nn.ReLU(), nn.Flatten(), nn.Linear(128 * 25 * 25, 10) ) def forward(self, x): return self.layers(x) # 学生模型(轻量化模型) class StudentModel(nn.Module): def __init__(self): super(StudentModel, self).__init__() self.layers = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3), nn.ReLU(), nn.Flatten(), nn.Linear(64 * 25 * 25, 10) ) def forward(self, x): return self.layers(x) # 损失函数(结合分类损失和蒸馏损失) def distillation_loss(student_logits, teacher_logits, labels, temperature=2.0): # 分类损失 ce_loss = nn.CrossEntropyLoss()(student_logits, labels) # 蒸馏损失(软目标) student_softmax = nn.functional.softmax(student_logits / temperature, dim=1) teacher_softmax = nn.functional.softmax(teacher_logits / temperature, dim=1) kl_divergence = nn.KLDivLoss(reduction='batchmean')(student_softmax.log(), teacher_softmax) return ce_loss + (kl_divergence * temperature ** 2) # 数据加载器(假设已有数据集) train_loader = DataLoader(dataset, batch_size=32, shuffle=True) # 初始化模型和优化器 teacher_model = TeacherModel() student_model = StudentModel() optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001) # 训练过程 for epoch in range(num_epochs): for images, labels in train_loader: # 前向传播 teacher_outputs = teacher_model(images) student_outputs = student_model(images) # 计算损失 loss = distillation_loss(student_outputs, teacher_outputs, labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}") # 测试学生模型 student_model.eval() test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = student_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of student model: {correct / total * 100:.2f}%")## 3. 量化技术(Quantization)
### 定点量化
直接将权重和激活值转换为低精度表示。例如,Post-Training Quantization(PTQ)是后训练量化,适用于已经训练好的模型。以下是一个简单的定点量化实现示例(使用PyTorch):
import torch from torch.quantization import QuantWrapper, default_qconfig # 加载预训练模型 model = MobileNetV2(pretrained=True) # 定义量化配置 qconfig = default_qconfig quantized_model = QuantWrapper(model) quantized_model.qconfig = qconfig # 量化准备和转换 torch.utils.quantization.prepare(quantized_model, inplace=True) torch.utils.quantization.convert(quantized_model, inplace=True) # 测试量化后的模型 test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = quantized_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of quantized model: {correct / total * 100:.2f}%")### 量化感知训练(QAT)
在训练过程中引入量化操作,通过反向传播优化量化后的参数。
以下是一个简单的QAT实现示例(使用PyTorch):import torch from torch.quantization import QuantWrapper, default_qat_qconfig # 加载预训练模型 model = MobileNetV2(pretrained=True) # 定义量化配置 qconfig = default_qat_qconfig quantized_model = QuantWrapper(model) quantized_model.qconfig = qconfig # 准备QAT torch.utils.quantization.prepare_qat(quantized_model, inplace=True) # 定义优化器和损失函数 optimizer = torch.optim.Adam(quantized_model.parameters(), lr=0.001) loss_fn = torch.nn.CrossEntropyLoss() # QAT训练过程 for epoch in range(num_epochs): for images, labels in train_loader: # 前向传播 outputs = quantized_model(images) loss = loss_fn(outputs, labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}") # 转换为量化模型 torch.utils.quantization.convert(quantized_model, inplace=True) # 测试最终模型 test_loader = DataLoader(test_dataset, batch_size=32) correct = 0 total = 0 with torch.no_grad(): for images, labels in test_loader: outputs = quantized_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of QAT model: {correct / total * 100:.2f}%")## 4. 混合精度训练
混合精度训练结合了FP16和INT8等不同精度的计算,可以在保持模型性能的同时显著提升计算效率。这种方法需要硬件支持(如NVIDIA的Tensor Core)。
# 四、模型压缩与量化的实际应用场景
## 1. 移动设备上的 AI 模型部署
在移动设备上运行大模型通常会面临计算资源和存储空间的限制。通过模型压缩与量化,可以在手机端实现高性能推理。例如,苹果的Core ML框架就集成了多种压缩与量化技术。
## 2. 嵌入式设备的轻量化需求
嵌入式设备(如智能家居、自动驾驶系统)通常具有严格的功耗和成本限制。通过剪枝和量化,可以将模型优化到满足这些设备的要求。
## 3. 物联网中的实时推理
在物联网场景中,设备通常需要进行实时推理,但计算资源有限。压缩与量化技术可以帮助模型在低功耗设备上快速运行。
## 4. 自动驾驶系统
自动驾驶系统对模型的实时性和准确性要求极高。通过压缩与量化技术,可以在保证性能的同时降低硬件成本。
# 五、未来发展方向
尽管模型压缩与量化已经取得了显著进展,但仍有许多值得探索的方向:
- 自动化压缩工具:开发更加智能化的压缩工具,能够根据具体场景自动选择最优的压缩策略。
- 端到端量化训练:将量化过程集成到模型训练中,进一步提升量化模型的性能。
- 稀疏计算硬件支持:随着稀疏计算技术的发展,硬件厂商可以为剪枝后的模型提供更好的支持。
# 六、总结
模型压缩与量化是推动深度学习技术落地的重要手段。通过减少模型的参数数量和计算复杂度,这一技术使得大模型能够在资源受限的环境中高效运行。未来,随着算法和硬件的不断进步,模型压缩与量化将在更多领域发挥重要作用。
DeepSeek生成的这篇文章,我也已经发表出来了,邀请大家观摩:模型压缩与量化:让大模型走向轻量化落地。大家可以看下它的质量怎么样?是不是非常棒!?
3. Chatbox接入API
除了直接使用网页端的在线服务,我们还可以将蓝耘提供的DeepSeek满血版服务以api的方式集成到其它应用中。
蓝耘元生代智算云平台提供了与OpenAI兼容的接口,可以直接使用 OpenAI 官方提供的 SDK 来调用大模型对话接口。只需要将 base_url 和 api_key 替换成相关配置,不需要对应用做额外修改,即可无缝将您的应用切换到相应的大模型。
base_url:https://maas-api.lanyun.net/v1
api_key:如需获取请参考获取API KEY
接口完整路径:https://maas-api.lanyun.net/v1/chat/completions
大家感兴趣的,可以自行去尝试下。本文主要为大家介绍另外一个方式,将DeepSeek接入到Chatbox中,构建一个智能化的聊天机器人。以下是具体步骤:
3.1 创建API KEY
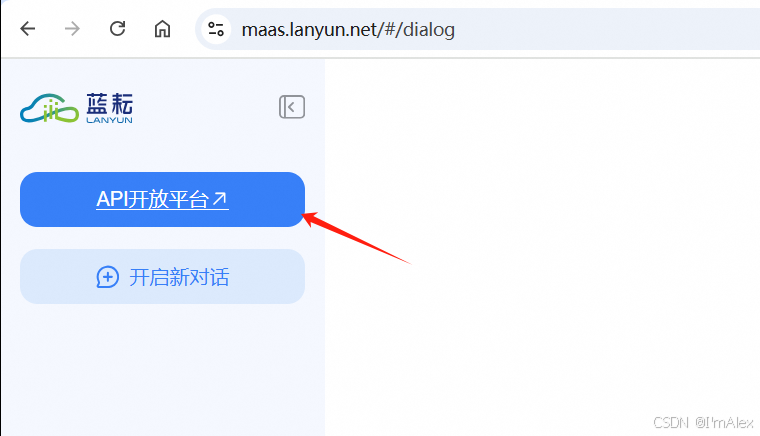
访问DeepSeek满血版页面,点击左上角的API开放平台。
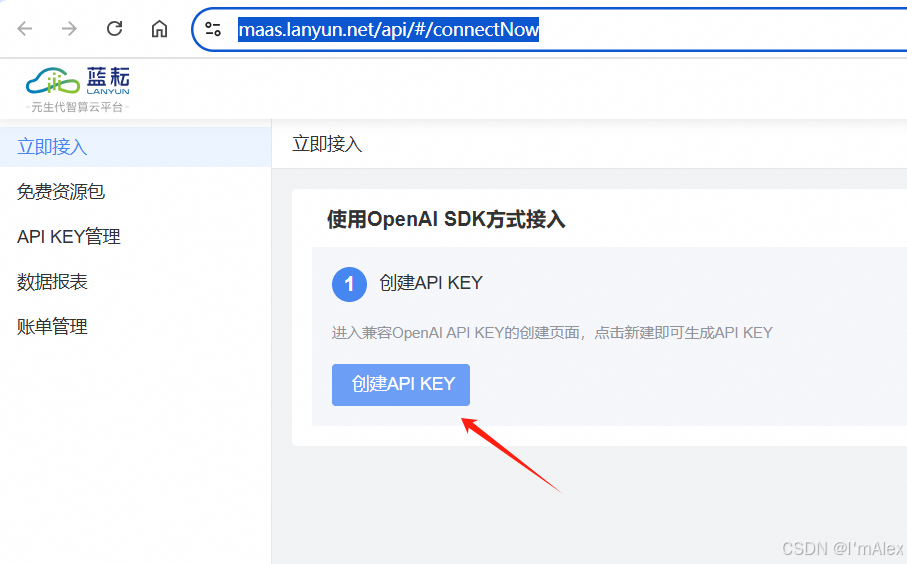
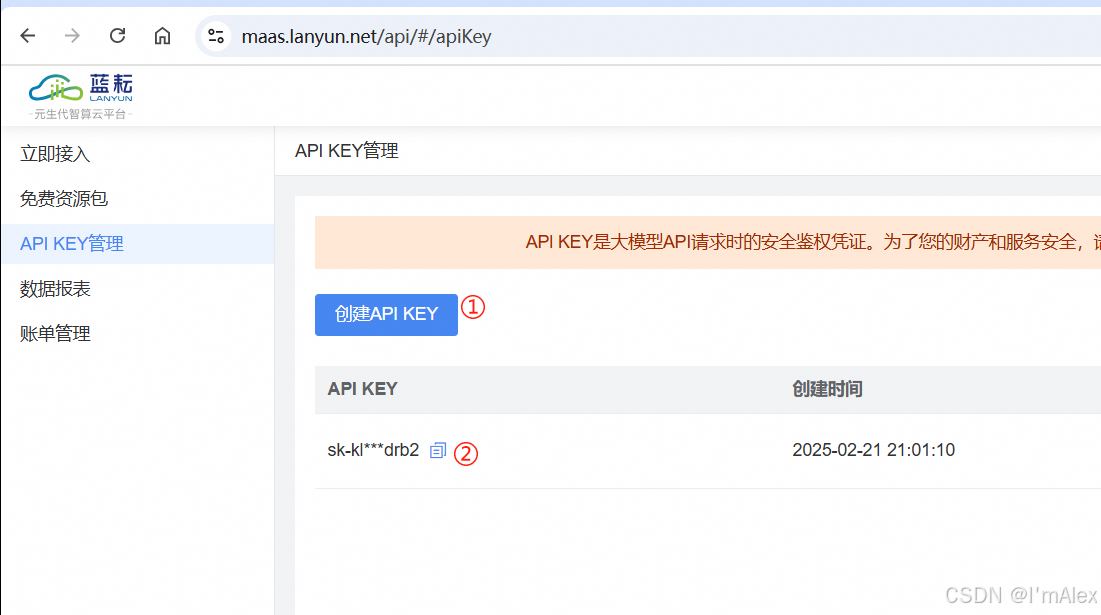
然后点击创建API KEY按钮生成一组API KEY,复制这组KEY,下面会用到。
3.2 下载安装Chatbox
Chatbox AI 是一款AI客户端应用和智能助手,支持众多先进的 AI 模型和 API。作为一个模型 API 和本地模型的连接工具,其主要功能一直都是完全免费的,非常推荐大家使用。

访问官网 https://chatboxai.app/zh 获取各平台版本(支持Windows/Mac/iOS/Android/Web),下载安装即可。文本以Windows版客户端为例进行演示。
3.3 配置DeepSeek
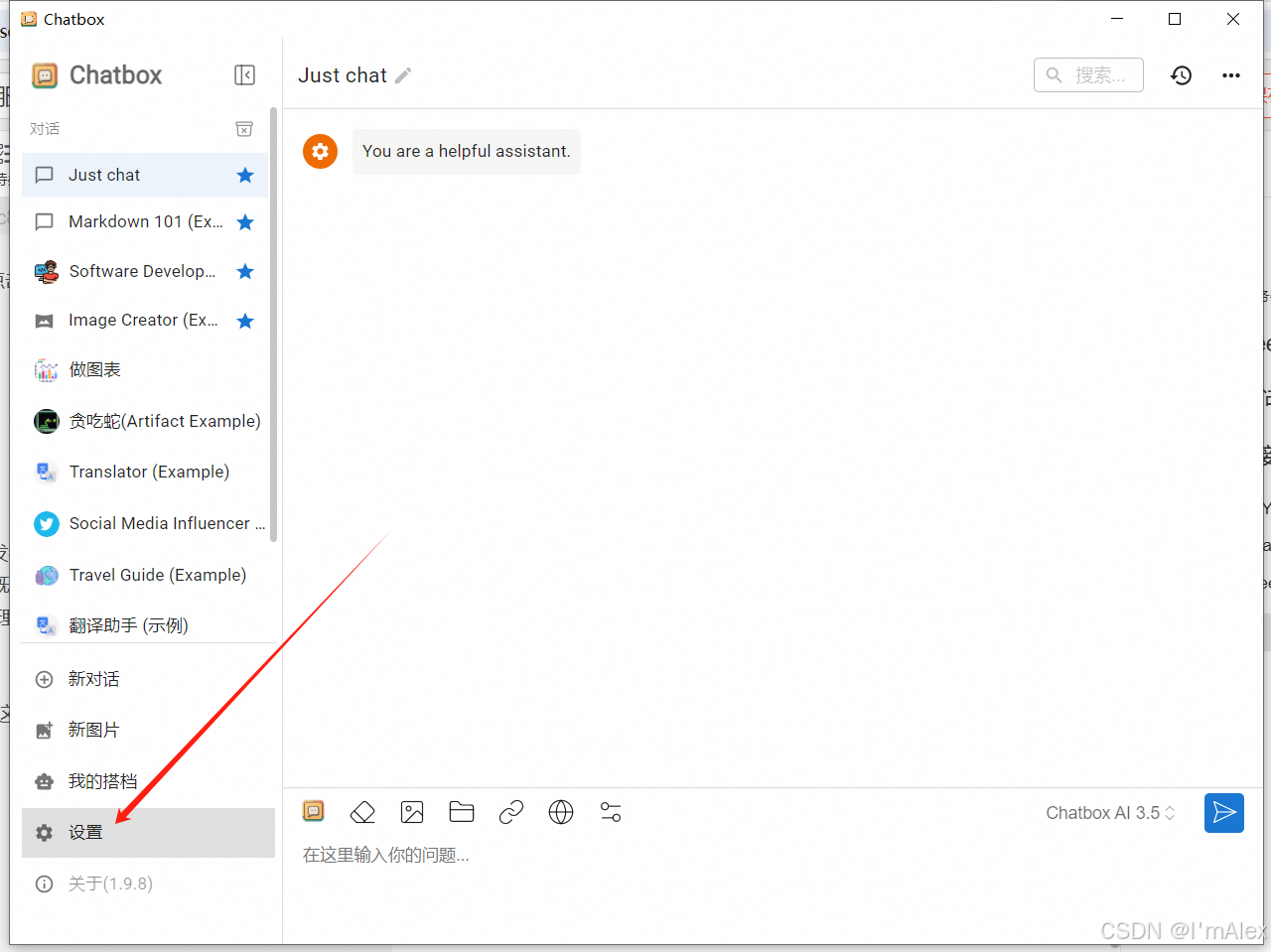
允许上一步安装好的chatbox,点击左下角的设置按钮。
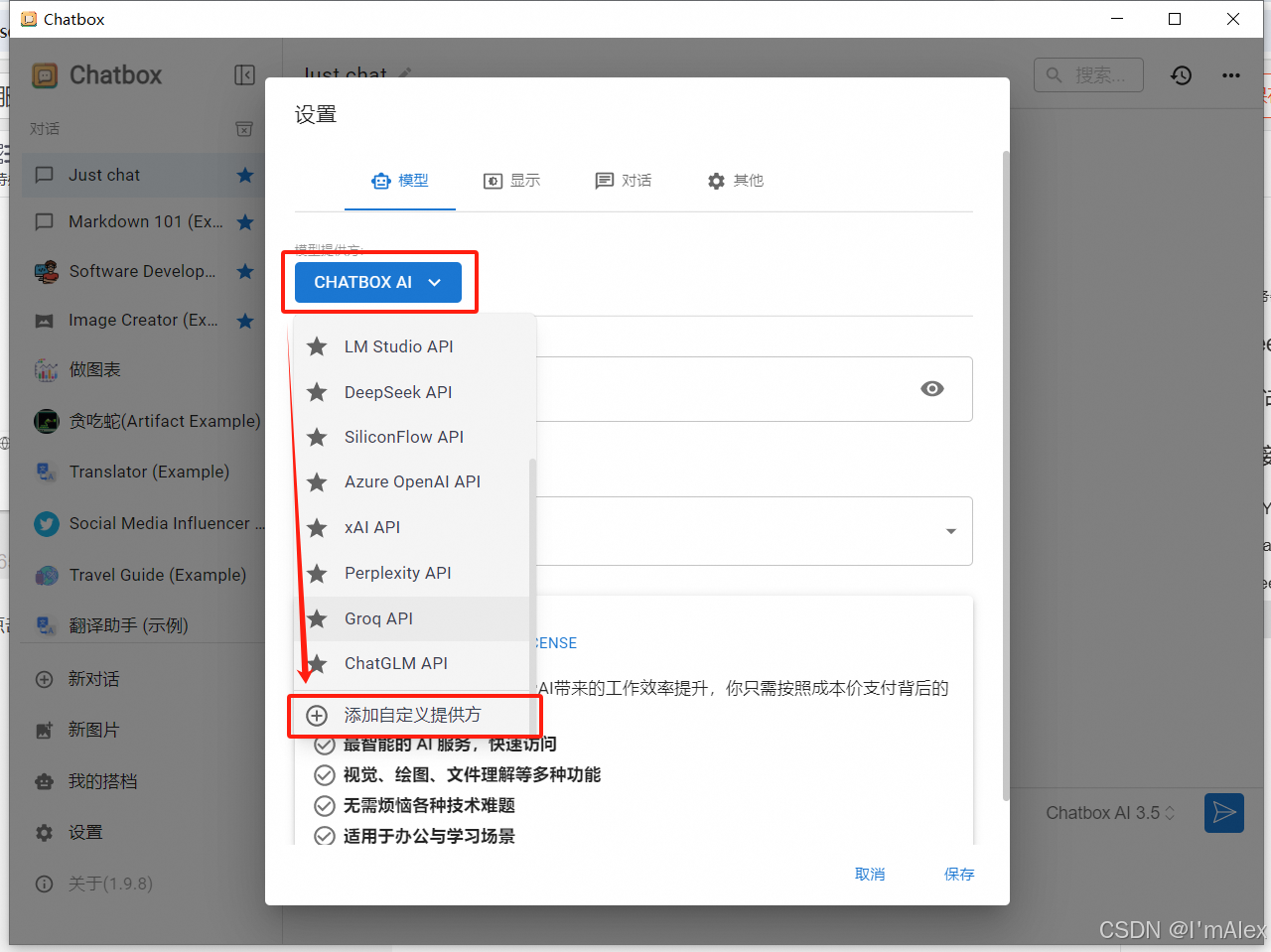
模型提供方拉到最下面,选择添加自定义提供方,然后从API模式就可以看到OpenAI API兼容了。
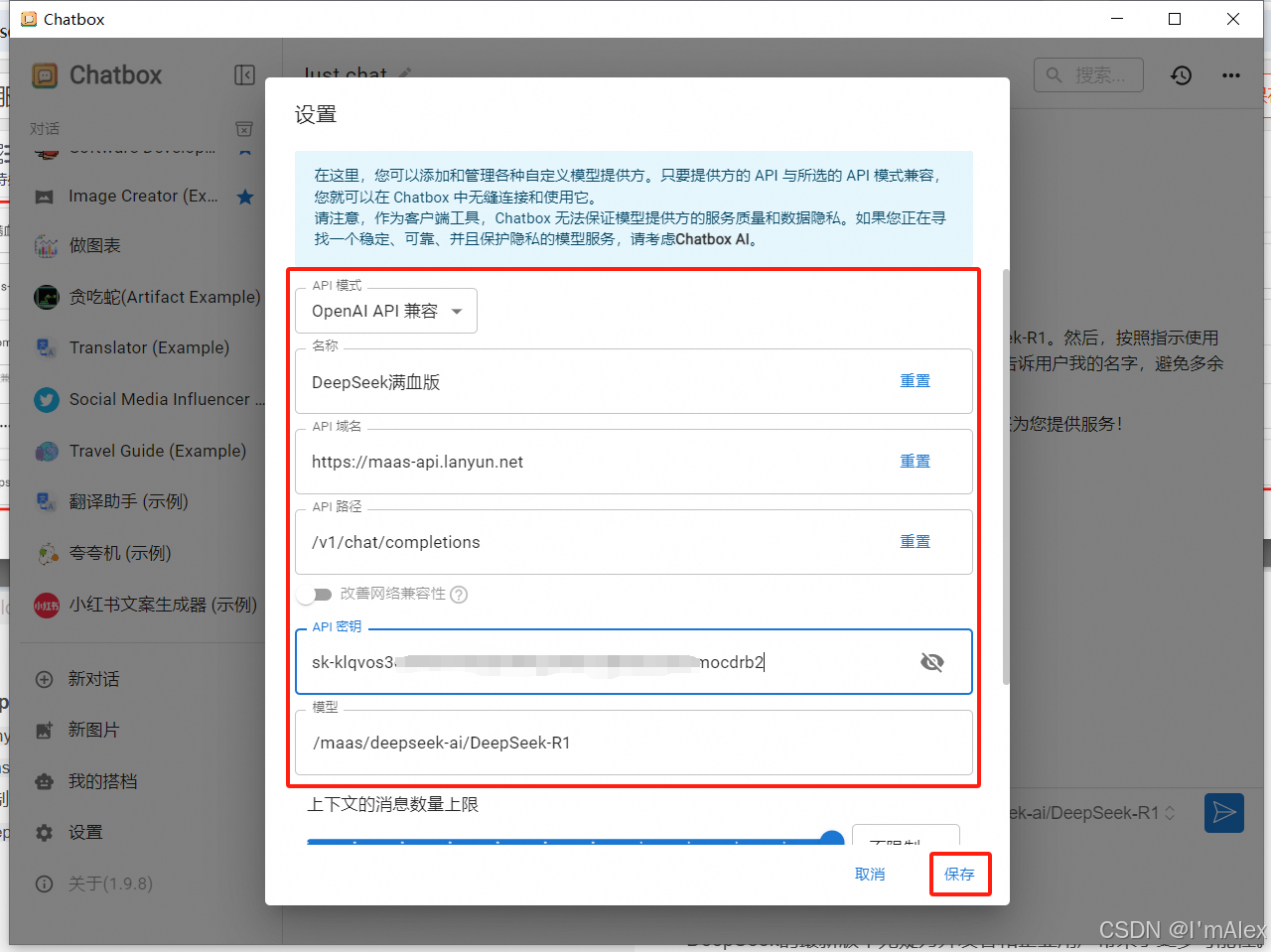
如上图所示,
- 名称:随便填,比如DeepSeep满血版。
- API域名:必须填
https://maas-api.lanyun.net。 - API路径:必须填
/v1/chat/completions。 - API秘钥:必须填第一步创建并复制好的API KEY。
- 模型:随便填,比如
/maas/deepseek-ai/DeepSeek-R1。
然后点击右下角的保存按钮,就完成添加了,是不是非常简单?
3.4 功能实测
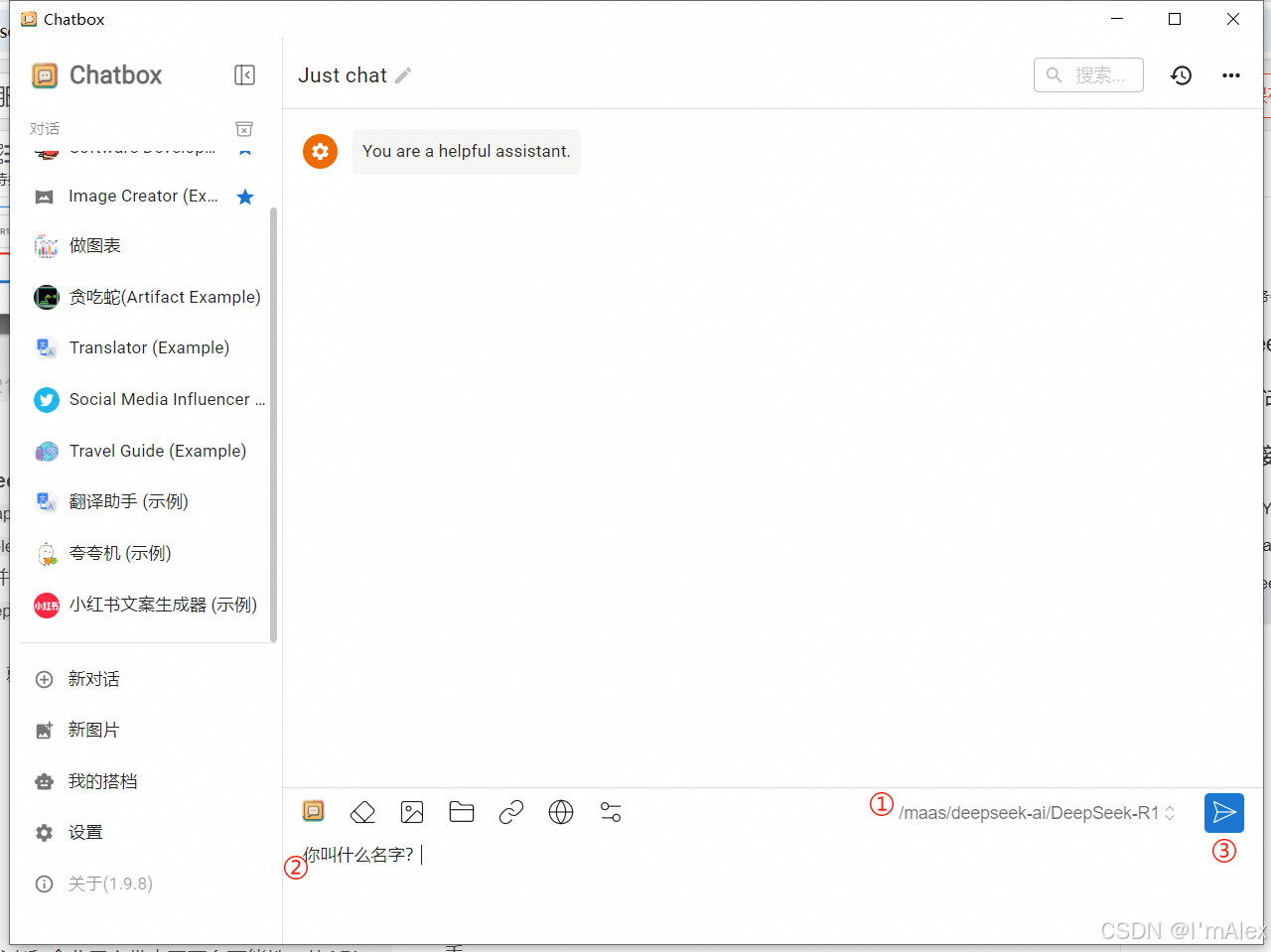
①选择上一步添加的模型,然后②输入问题,点击③发送按钮。如果能正常回复,就说明我们前面的配置已经成功了。
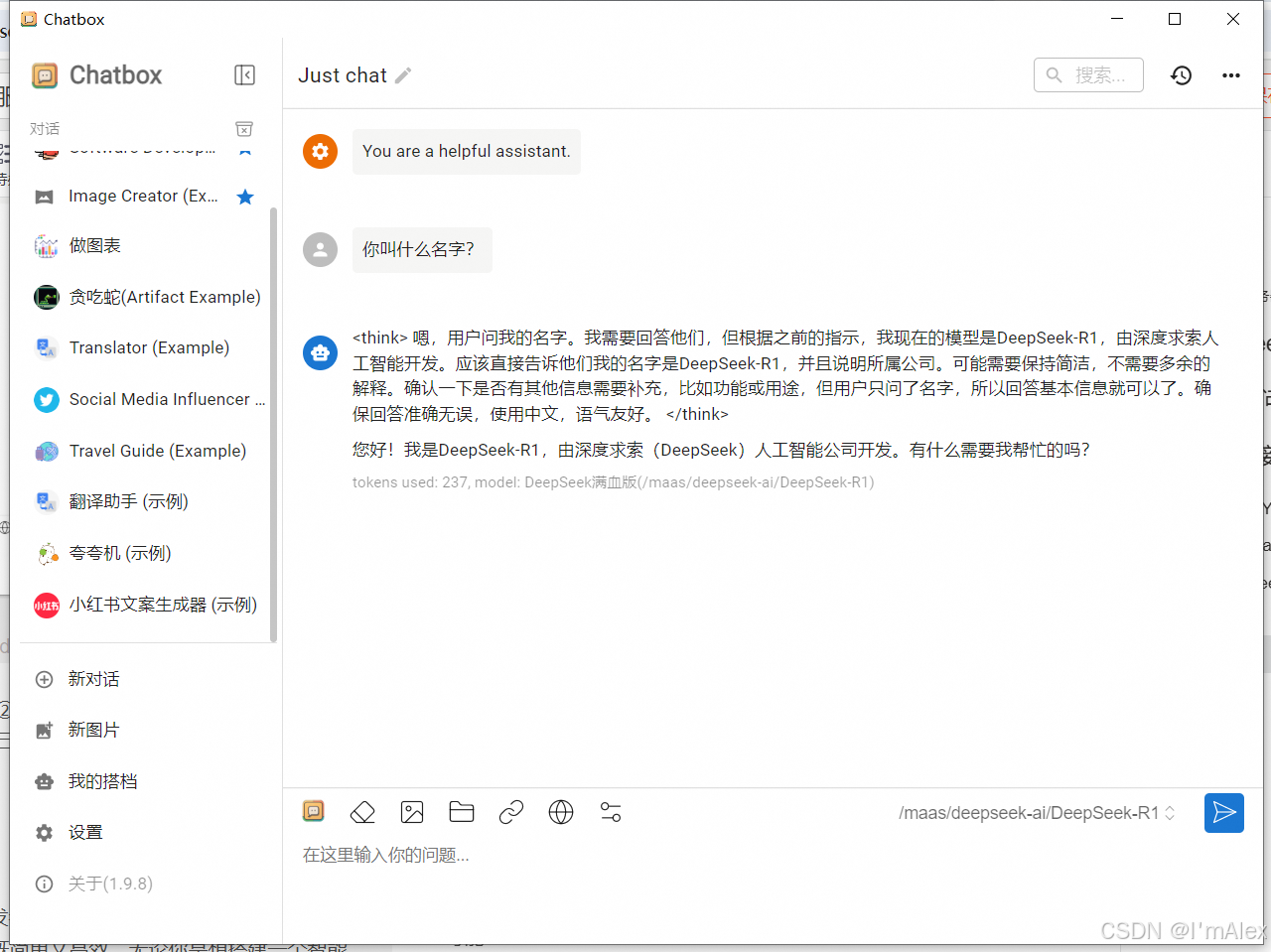
如上图所示,就表示添加成功,可以正常使用了。接下来我们让chatBox里的DeepSeek再给我们写一篇技术博客,看看它的响应速度如何。
测试下来,响应还是比较迅速的,也有思考过程。下面是DeepSeek的生成的完整文章:
引言
在当今科技飞速发展的时代,人工智能已然成为推动各领域变革的核心力量,其中自然语言处理(NLP)更是取得了令人惊叹的成就。在这片充满创新与突破的领域中,DeepSeek与ChatGPT犹如两颗璀璨的明星,吸引了全球开发者、研究人员以及广大普通用户的目光。它们代表着当前AI语言模型的顶尖水准,引领着自然语言处理技术的前沿发展。然而,随着两者在众多应用场景中的广泛使用,一个备受关注的问题也随之而来:究竟谁能在这场激烈的竞争中脱颖而出,荣膺“AI语言之王”的称号?这不仅关乎技术的较量,更对未来自然语言处理的发展方向有着深远影响。本文将从多个维度对DeepSeek和ChatGPT进行深入剖析,包括模型架构、性能表现、应用场景、代码实现等方面,力求为读者呈现一场全面且深入的终极对决。
一、模型架构探秘
1.1 ChatGPT的架构
ChatGPT基于GPT(Generative Pretrained Transformer)架构。GPT系列模型采用了Transformer架构,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),以自注意力机制(Self - Attention)为核心。自注意力机制能够让模型在处理序列数据时,同时关注序列中的不同位置,从而更有效地捕捉长距离依赖关系。在GPT模型中,Transformer由多层的编码器和解码器组成。在预训练阶段,模型通过大量的无监督文本数据进行训练,学习到通用的语言表示。然后在微调阶段,可以根据具体的任务需求,如文本生成、问答系统等,对模型进行进一步的训练。
1.2 DeepSeek的架构
DeepSeek同样基于Transformer架构,但在一些细节上进行了优化和创新。它可能在层数、头数、嵌入维度等超参数上进行了调整,以适应不同的数据集和任务需求。例如,DeepSeek可能增加了更多的隐藏层,以提高模型的表示能力;或者优化了注意力机制的计算方式,使其在处理大规模数据时更加高效。此外,DeepSeek可能在预训练阶段采用了独特的数据处理方式,比如使用了更广泛的数据源,包括不同领域、不同语言的文本,以增强模型的泛化能力。同时,在微调阶段,可能设计了更灵活的微调策略,能够更好地适应多样化的下游任务。
二、性能表现大比拼
2.1 语言理解能力
为了评估两者的语言理解能力,我们可以使用GLUE(General Language Understanding Evaluation)基准测试。GLUE包含了多种自然语言理解任务,如文本蕴含、情感分析、语义相似度等。在文本蕴含任务中,给定一个前提文本和一个假设文本,模型需要判断假设文本是否能从前提文本中合理推断出来。例如:
前提:“一群人在公园里开心地玩耍。”
假设:“有些人在户外享受时光。”在情感分析任务中,模型需要判断一段文本表达的情感是积极、消极还是中性。以影评为例:
“这部电影的剧情紧凑,特效震撼,真的太棒了!” - 积极情感从公开的评测结果来看,ChatGPT在GLUE基准测试中取得了相当不错的成绩,展现出了强大的语言理解能力。而DeepSeek也不甘示弱,在部分任务上甚至超越了ChatGPT。这可能得益于DeepSeek在预训练过程中对多样化数据的学习,使其能够更好地理解复杂的语言语义。
2.2 文本生成质量
对于文本生成任务,我们可以从生成文本的连贯性、逻辑性和创新性等方面进行评估。以故事生成任务为例,给定一个开头:“在一个神秘的森林里,住着一个勇敢的小探险家。” 优秀的模型生成的故事应该具有连贯的情节发展,逻辑合理,并且具有一定的创新性。
ChatGPT生成的文本通常具有较高的连贯性,能够根据给定的开头展开丰富的想象,构建出一个相对完整的故事。然而,有时可能会出现一些重复或模式化的表述。
DeepSeek在生成文本时,注重逻辑性和创新性的平衡。它能够生成既符合逻辑又富有新意的故事,在情节转折和细节描写上可能会给人带来更多的惊喜。例如,在一些科幻故事生成中,DeepSeek可能会引入独特的科技设定和世界观,使故事更具吸引力。
2.3 多语言支持
在全球化的今天,多语言支持能力至关重要。ChatGPT在多语言方面有一定的表现,能够处理多种常见语言的文本。但对于一些小众语言或特定领域的专业术语,可能存在理解和生成不准确的问题。DeepSeek则在多语言支持上投入了更多的精力。它通过大规模的多语言数据预训练,对不同语言的语法、语义和文化背景有更深入的理解。在翻译任务中,DeepSeek能够更准确地将源语言翻译成目标语言,并且在生成多语言文本时,能够遵循相应语言的表达习惯。例如,在将中文古诗翻译成英文时,DeepSeek能够更好地保留原诗的意境和韵律。
三、应用场景剖析
3.1 聊天机器人
ChatGPT因其出色的语言交互能力,被广泛应用于聊天机器人领域。它可以与用户进行自然流畅的对话,回答各种问题,从日常闲聊到专业知识咨询。例如,在智能客服场景中,ChatGPT能够快速理解用户的问题,并提供准确的解决方案,大大提高了客户服务的效率。DeepSeek同样适用于聊天机器人场景,并且在一些特定领域的聊天机器人中有独特的优势。比如在医疗领域,DeepSeek可以利用其对医学术语的准确理解和对医学知识的掌握,为患者提供更专业、准确的健康咨询服务。它能够更好地理解患者描述的症状,并给出合理的诊断建议和治疗方案。
3.2 内容创作
在内容创作领域,ChatGPT可以帮助作家生成故事大纲、创作诗歌、撰写新闻报道等。它能够快速生成大量的文本素材,为创作者提供灵感。然而,由于其生成的内容可能存在一定的模式化,有时需要创作者进行进一步的润色和修改。DeepSeek在内容创作方面则更具个性化。它可以根据创作者的风格偏好和需求,生成更符合其期望的内容。例如,对于一位擅长奇幻风格的作家,DeepSeek可以生成具有独特奇幻设定和精彩情节的故事,帮助作家节省创作时间,同时保持作品的独特风格。
3.3 智能辅助写作
在智能辅助写作方面,两者都能发挥重要作用。当用户在撰写文档时,它们可以提供语法检查、词汇推荐、语句润色等功能。ChatGPT的语法检查功能较为全面,能够识别常见的语法错误并给出修改建议。词汇推荐也比较丰富,能够根据上下文提供合适的词汇选择。DeepSeek在智能辅助写作中更注重语义的优化。它不仅能够检查语法错误,还能深入理解句子的语义,提出更合理的语义调整建议。例如,当用户表达一个观点时,DeepSeek可以帮助用户更清晰、准确地阐述观点,使文章的逻辑性更强。
四、代码实现与应用示例(Java语言)
4.1 使用ChatGPT API进行文本生成
首先,需要获取ChatGPT的API密钥。假设已经获取了API密钥,以下是使用Java调用ChatGPT API进行文本生成的示例代码:import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStream; import java.net.HttpURLConnection; import java.net.URL; import java.nio.charset.StandardCharsets; import com.google.gson.JsonObject; import com.google.gson.JsonParser; public class ChatGPTTextGenerator { private static final String API_URL = "https://api.openai.com/v1/engines/davinci/completions"; private static final String API_KEY = "YOUR_API_KEY"; public static String generateText(String prompt) { try { URL url = new URL(API_URL); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setRequestMethod("POST"); connection.setRequestProperty("Content-Type", "application/json"); connection.setRequestProperty("Authorization", "Bearer " + API_KEY); connection.setDoOutput(true); JsonObject requestBody = new JsonObject(); requestBody.addProperty("prompt", prompt); requestBody.addProperty("max_tokens", 100); try (OutputStream os = connection.getOutputStream()) { byte[] input = requestBody.toString().getBytes(StandardCharsets.UTF_8); os.write(input, 0, input.length); } try (BufferedReader br = new BufferedReader( new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8))) { StringBuilder response = new StringBuilder(); String responseLine; while ((responseLine = br.readLine())!= null) { response.append(responseLine.trim()); } JsonObject jsonResponse = JsonParser.parseString(response.toString()).getAsJsonObject(); return jsonResponse.getAsJsonArray("choices").get(0).getAsJsonObject().get("text").getAsString(); } } catch (IOException e) { e.printStackTrace(); return null; } } public static void main(String[] args) { String prompt = "写一篇关于春天的短文"; String generatedText = generateText(prompt); System.out.println(generatedText); } }4.2 使用DeepSeek相关SDK进行文本处理
假设DeepSeek提供了Java SDK,以下是一个简单的文本情感分析示例代码:import com.deepseek.sdk.SentimentAnalyzer; import com.deepseek.sdk.SentimentResult; public class DeepSeekSentimentAnalysis { public static void main(String[] args) { String text = "这部电影真的太糟糕了,剧情混乱,演员演技也很差。"; SentimentAnalyzer analyzer = new SentimentAnalyzer(); SentimentResult result = analyzer.analyze(text); System.out.println("情感倾向: " + result.getSentiment()); System.out.println("置信度: " + result.getConfidence()); }在上述代码中,SentimentAnalyzer是DeepSeek SDK提供的用于情感分析的类,analyze方法接受一段文本并返回情感分析结果,包括情感倾向(如积极、消极、中性)和置信度。
五、成本与可扩展性考量
5.1 成本分析
使用ChatGPT API需要根据使用的资源量支付费用。例如,文本生成的长度、调用的频率等都会影响成本。对于大规模的应用场景,如企业级的智能客服系统,成本可能会成为一个重要的考量因素。DeepSeek在成本方面可能具有一定的优势。如果其采用了更高效的模型架构和训练算法,那么在处理相同规模的任务时,可能会消耗更少的计算资源,从而降低成本。此外,DeepSeek可能会提供更灵活的收费模式,以满足不同用户的需求。
5.2 可扩展性
随着业务的增长和数据量的增加,模型的可扩展性至关重要。ChatGPT在可扩展性方面已经经过了大规模应用的验证,OpenAI通过不断优化基础设施和算法,能够支持大量用户的同时请求。DeepSeek也在积极探索可扩展性的解决方案。它可能采用分布式训练和推理技术,以提高模型在大规模数据和高并发场景下的性能。同时,通过对模型架构的优化,使得在增加计算资源时能够更有效地提升处理能力。
六、安全性与隐私保护
6.1 ChatGPT的安全性与隐私
ChatGPT在安全性和隐私保护方面采取了一系列措施。OpenAI对用户输入的数据进行严格的审查和过滤,以防止恶意使用,如生成有害信息、侵犯他人隐私等。同时,在数据存储和传输过程中,采用了加密技术,保障用户数据的安全。然而,由于其基于云服务的特性,用户可能会担心数据是否会被不当使用或泄露。虽然OpenAI承诺遵守严格的隐私政策,但在实际应用中,仍然需要用户谨慎评估风险。
6.2 DeepSeek的安全性与隐私
DeepSeek同样重视安全性和隐私保护。它可能采用了更严格的数据访问控制机制,确保只有经过授权的人员才能访问用户数据。在数据处理过程中,采用匿名化和加密技术,进一步保护用户的隐私。此外,DeepSeek可能会在模型训练过程中采用联邦学习等技术,使得数据可以在本地进行训练,而无需上传到中央服务器,从而最大程度地保护用户数据的隐私。
七、未来发展趋势展望
7.1 ChatGPT的未来发展
ChatGPT未来可能会在模型架构上进一步创新,提高模型的性能和效率。例如,探索更先进的自注意力机制变体,以更好地处理超长文本和复杂的语言结构。同时,OpenAI可能会加强多模态能力的开发,使其不仅能够处理文本,还能与图像、音频等其他模态的数据进行交互。在应用方面,ChatGPT可能会深入更多的垂直领域,如金融、法律等,为这些领域提供更专业、精准的服务。通过与行业专家的合作,对模型进行更有针对性的训练,以满足特定领域的需求。
7.2 DeepSeek的未来发展
DeepSeek未来可能会继续优化其模型架构,在保持高性能的同时,进一步降低计算成本。它可能会在多语言和跨文化理解方面取得更大的突破,为全球用户提供更优质的服务。在应用场景上,DeepSeek可能会专注于一些特定的细分领域,打造具有差异化竞争优势的产品。例如,在教育领域,开发出更智能的学习辅助工具,帮助学生提高学习效果;在科研领域,协助研究人员进行文献综述和数据分析。
八、结论
DeepSeek和ChatGPT都是AI语言模型领域的杰出代表,它们在模型架构、性能表现、应用场景等方面各有千秋。ChatGPT凭借其广泛的知名度和强大的语言交互能力,在聊天机器人和通用内容创作等领域有着广泛的应用。而DeepSeek则通过在模型优化、多语言支持和特定领域应用等方面的优势,展现出了巨大的潜力。在这场终极对决中,很难简单地判定谁是绝对的“AI语言之王”。最终的选择取决于具体的应用场景和用户需求。对于注重通用语言交互和快速获取灵感的用户,ChatGPT可能是更好的选择;而对于需要专业领域支持、多语言处理和个性化内容生成的用户,DeepSeek可能更能满足其需求。
随着AI技术的不断发展,我们有理由相信,DeepSeek和ChatGPT将继续推动自然语言处理领域的进步,为我们带来更多的惊喜和便利。无论是在智能客服、内容创作还是其他领域,它们都将发挥越来越重要的作用,共同塑造一个更加智能的未来。
可以看到,蓝耘元生代智算云平台提供的满血版DeepSeek,在文本生成质量还是非常不错的,内容也很全面。
3.5 注意事项
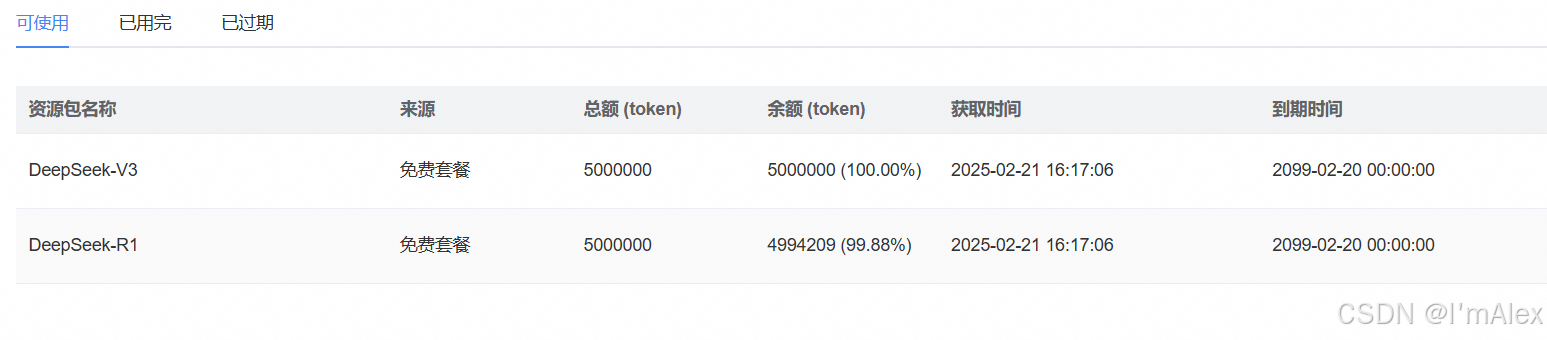
蓝耘元生代智算云平台为大家提供了累计1000W(V3和R1各500W)的免费token数,够大家使用到天荒地老了,哈哈哈。可以在免费资源包中查看token使用情况。
注意事项:
请妥善保存好API KEY,强烈建议您不要将其直接写入到调用模型的代码中。
创建完成后,可进入API KEY管理,进行新增、查看及删除操作。
4. 总结
DeepSeek的最新版本无疑为开发者和企业用户带来了更多可能性。从API接入到Chatbox集成,整个过程既简单又高效。无论你是想搭建一个智能客服系统,还是开发一款个人助理应用,蓝耘元生代智算云平提供的DeepSeek服务都能成为你的得力助手。
现在就行动起来,赶紧去试试这个“满血版”的DeepSeek:https://cloud.lanyun.net//#/registerPage?promoterCode=0131,解锁无限创意可能吧。