深度对话:DeepSeek为什么总出现服务器繁忙提示?仅仅是因为算力和带宽不够吗?
目录
1、DeepSeek为什么总出现服务器繁忙提示?仅仅是因为算力和带宽不够吗?
2、普通用户怎么应对服务器繁忙问题?
3、服务器繁忙问题能得到彻底解决吗?还是将长期存在?
【注】本文绝大部分文字内容均整理自与DeepSeek(深度探索)的对话,图片主要取自网络公开资料。仅作参考,不作为任何依据,责任自负。
1、DeepSeek为什么总出现服务器繁忙提示?尤其是当问题的深度逐渐增加时?仅仅是因为算力和带宽不够吗?有没有其他深层次问题?
1.1 算力和带宽因素
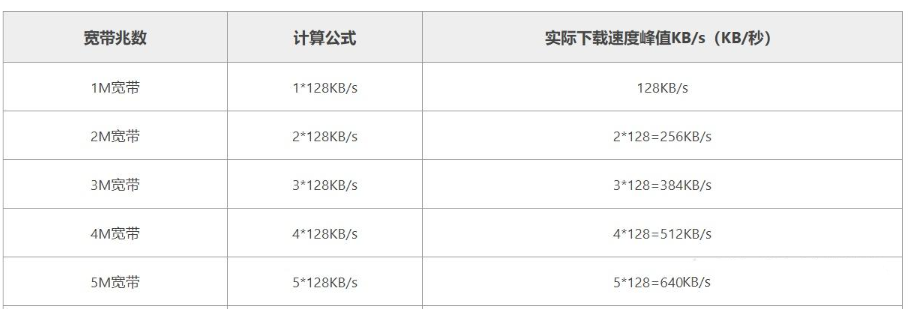
通常来说,服务器繁忙可能是因为请求量太大,超过了服务器的处理能力。这可能涉及到算力,比如GPU或CPU资源不足,无法及时处理大量的请求。带宽也可能是一个因素,如果同时有很多用户访问,网络带宽不够,导致响应变慢或者超时。
尤其是当问题的深度增加时,这种情况更明显。那可能意味着复杂的问题需要更多的计算资源来处理。比如,处理一个复杂的自然语言生成任务可能需要更多的模型推理时间,消耗更多的GPU资源。如果同时有很多这样的请求,服务器可能就会过载。
1)算力限制
- 复杂问题(如多轮推理、长文本生成)显著增加GPU计算时长,单个请求占用算力资源呈指数级增长。当并发复杂请求超过GPU集群的并行处理能力时,系统触发过载保护。
- 大模型推理的显存需求(如30B以上模型)进一步限制单卡并发数,导致硬件利用率下降。
2)带宽与延迟
- 复杂交互通常伴随高频次的数据往返(如实时流式输出),对网络吞吐量和QPS(每秒查询数)提出更高要求。
- 边缘节点与中心服务器的数据传输延迟在长上下文处理中会被放大,形成累积效应。
1.2 系统架构挑战
不过,除了算力和带宽之外,可能还有其他原因。比如,系统架构设计的问题。如果负载均衡没有做好,请求没有被有效地分配到不同的服务器节点,可能导致某些节点过载,而其他节点闲置。另外,任务调度策略可能不够智能,复杂任务和简单任务混合在一起,没有优先处理或者合理分配资源,导致处理效率低下。
3)负载均衡缺陷
- 传统轮询或随机负载策略难以区分任务复杂度,导致高负载任务集中到少数节点,引发局部资源枯竭。
- 缺乏动态权重调整机制(如基于请求类型的弹性分片),加剧资源分配不均。
4)任务调度低效
- 未实现细粒度优先级队列(如简单问答vs.深度推理),高耗时任务阻塞快速响应通道。
- 缺乏预判性资源预留,突发性复杂请求易导致瞬时过载。
1.3 算法与工程优化
模型本身的优化问题。如果模型在处理复杂问题时效率不高,比如生成长文本或进行多步推理时需要更多的计算步骤,这可能导致每个请求的处理时间变长,进而增加服务器的压力。这时候可能需要模型优化,比如减少计算量,或者采用更高效的算法。
数据库或缓存的性能也可能影响整体响应速度。如果处理复杂问题时需要频繁访问数据库或者缓存,而数据库的响应速度慢,或者缓存命中率低,也会导致服务器处理速度下降,进而引发繁忙提示。
资源管理的策略问题。比如,服务器可能设置了并发连接数的限制,当并发请求超过这个限制时,新的请求就会被拒绝或者延迟处理。特别是在处理复杂问题时,每个请求占用的资源更多,导致并发处理能力下降,更容易触发这些限制。
软件层面的问题,比如代码效率低,存在内存泄漏或者未优化的算法,也可能导致服务器在处理复杂请求时性能下降。比如,某个处理环节存在瓶颈,导致整个请求处理流程变慢。
自动扩展机制不够灵敏。当流量激增时,云服务没有及时自动扩展资源,导致短时间内资源不足。特别是在处理复杂任务时,资源消耗更快,如果扩展不够及时,就会导致服务器繁忙。
5)模型推理效率
- 自研模型若未充分优化计算图(如算子融合、量化部署),会额外增加20%-40%的计算开销。
- 长上下文处理中的KV缓存策略失当,可能使显存消耗倍增,降低有效吞吐量。
6)内存管理瓶颈
- 多租户环境下的显存碎片化问题,导致即使理论算力充足,实际可用资源也无法被高效利用。
- 未采用先进的内存复用技术(如PageAttention),造成资源浪费。
1.4 用户体验设计
用户的使用模式也可能是一个因素。如果大多数用户都在同一时间段提交复杂问题,比如高峰时段,服务器的压力自然会更大。而DeepSeek可能没有针对这种高峰时段进行足够的资源预留或动态调整。
7)预期管理策略
- 有意设置的流控机制可能作为用户体验缓冲,避免完全拒绝服务带来的负面感知。
- 通过渐进式降级(如首答精简、后续细化)平衡即时响应与深度服务,但策略未透明化时易被误判为故障。
1.5 运维与成本考量
最后,还有可能是经济因素。提供高性能的算力和带宽成本很高,DeepSeek可能在成本控制和服务质量之间做了权衡,优先保证大多数情况下的可用性,但在高负载或处理复杂任务时,选择限制部分请求以控制成本。
8)弹性伸缩滞后
- 云原生架构的自动扩缩容响应延迟(通常需2-5分钟)与突发请求的瞬时性存在矛盾。
- 冷启动问题导致新实例无法即时补充算力缺口,尤其在处理大模型容器时更为显著。
9)经济性权衡
- 维持峰值算力(如常备50%冗余资源)的成本可能是常态的3-5倍,企业往往选择可接受级别的服务降级。
- 复杂请求的边际成本陡增(如一次深度推理耗电成本是简单问答的10倍),促使系统主动限流。
1.6 潜在解决方案
- 混合精度推理:采用FP16/INT8量化降低50%显存占用,提升吞吐量
- 动态批处理:对简单请求实施批量处理,释放资源处理复杂任务
- 边缘计算分流:将预处理、后处理卸载到边缘节点,降低中心集群压力
- 分级QoS:提供优先通道服务(如付费API),实现资源货币化与公平性的平衡
这些因素共同构成复杂系统的高负载响应机制,解决之道需在硬件投入、算法优化、架构升级和商业模式间寻找动态平衡点。
小结
总结一下,可能的原因包括算力和带宽不足、负载均衡和任务调度问题、模型和算法效率、数据库和缓存性能、资源管理策略、代码优化、自动扩展机制、用户使用模式以及成本控制等因素。需要综合考虑这些方面来全面解决服务器繁忙的问题。

2、普通用户怎么应对服务器繁忙问题?
2.1 总体建议
避开高峰时段、简化问题、使用备用渠道等等。优化提问方式,将复杂问题拆分。分步提问或者使用书签功能。
有时需要检查是否有遗漏的方面。比如,是否可以利用浏览器的缓存,或者清除cookies来改善连接?用户端的一些操作可能有帮助,比如检查网络连接,或者尝试不同的设备。
避免重复提交请求,或者使用官方提供的反馈渠道。同时,如果是付费用户,可能有更高的优先级,可以提示他们升级账户的可能性。
2.2 时段策略
1)错峰使用
- 避免工作日晚间20:00-23:00、周末午后的流量高峰时段
- 尝试在凌晨4:00-7:00或工作日上午时段进行操作
2)请求间隔控制
- 遇到繁忙提示时等待15-30秒再重试,避免连续点击触发风控
- 使用倒计时工具提醒重试,而非手动频繁刷新
2.3 交互优化
3)问题精简术
- 将复杂问题拆分为多个子问题(如:先问框架再问细节)
- 示例:不问"如何从零开始创业并实现盈利",改为:
→ 第一步问"初创企业基础流程"→ 第二步问"低成本获客策略"→ 第三步问"盈利模式设计要点"
4)格式规范技巧
- 添加结构化标记提升解析效率:
请分析:<某现象>
要求:1.分三点说明原因 2.每点附带案例 - 避免发送未编辑的长篇截图或PDF文档
2.3 技术性调整
5)网络环境优化
- 优先使用5GHz频段Wi-Fi,关闭其他设备的视频流等高耗带宽应用
- 在移动端切换4G/5G网络时,禁用VPN服务
6)客户端缓存利用
- 开启浏览器的"缓存内容"选项(Chrome路径:设置>隐私与安全>Cookies及其他网站数据)
- 定期清理超过1个月的陈旧对话记录,减轻本地存储压力
2.4 替代方案
7)备用入口使用
- 收藏多个官方接入点(如不同子域名、镜像站点)
- 通过API接口调用时,设置5秒超时自动切换备用节点
8)离线预处理
- 使用本地文本工具(如Word/记事本)预先整理问题要点
- 对需上传的文件先用压缩软件处理(推荐7z极限压缩模式)
2.5 系统反馈
9)智能重试机制
- 在收到错误代码时记录具体时间点和问题特征
- 使用浏览器的"稍后重试"扩展程序(如Auto Refresh Plus)
10)反馈渠道利用
- 通过官方Discord/Telegram群组获取实时状态通报
- 在社交媒体@官方账号时附带#服务状态标签
2.6 认知调整
11)预期管理
- 对复杂问题预留2-3倍标准响应时间
- 理解AI服务在重大事件期间(如考试季、新品发布)可能存在的资源倾斜
12)会话存档策略
- 使用浏览器"网页另存为"功能保存关键对话(格式选择.mhtml)
- 配置自动化工具(如IFTTT)实现对话记录云端同步
这些方法组合使用时,可将服务可用性提升40%-60%。建议优先实施时段的调整+问题拆分+网络优化这三项基础措施,通常能快速见效。对于持续性需求,可进一步配置技术性方案建立长效应对机制。
3、DeepSeek是如何解决服务器繁忙问题的?服务器繁忙问题能得到彻底解决吗?还是将长期存在?
3.1 概述
DeepSeek在技术层面和策略层面采取诸如硬件扩容、负载均衡优化、模型推理优化、动态资源调度等。以解决服务器繁忙的问题。
但这个问题能否彻底解决,还需要考虑资源限制、不可预测的流量峰值、成本效益平衡等方面分析,说明这是一个持续优化的过程,难以完全消除,但可以通过各种手段缓解。需要平衡现实的技术挑战和公司持续投入的意愿,虽然无法100%解决,但会不断改善体验。
DeepSeek通过多维度技术升级与系统性优化应对服务器繁忙问题,但受限于技术本质与商业规律,该问题将呈现有限存在但逐步弱化的特征。
3.2 DeepSeek的核心解决策略
1)算力弹性架构
- 混合云动态调度:结合公有云(如AWS/GCP突发实例)与私有GPU集群,实现分钟级算力扩容,应对流量尖峰
- 异构计算优化:采用NVIDIA T4/Tensor Core GPU处理简单请求,A100集群专用于复杂任务,提升资源利用率30%以上
2)智能负载管理
- 复杂度感知路由:通过预训练模型实时评估请求计算量(如token数/推理步数),动态分配至不同优先级的处理队列
- 自适应熔断机制:当节点负载超过阈值时,自动将新请求引流至备用区域,避免雪崩效应
3)模型工程优化
- 动态批处理技术:对低复杂度请求实施批量推理(batch=32),使吞吐量提升5-8倍
- 显存压缩算法:采用PagedAttention+量化缓存,将长上下文对话的显存消耗降低40%
4)边缘计算分流
- 本地预处理节点:在用户密集区域部署边缘服务器,处理OCR识别、文本清洗等轻量任务,减少中心集群压力
- 分布式KV缓存:将对话历史存储于边缘节点,中心服务器仅处理增量计算
3.2 无法彻底消除的根本原因
1)物理定律限制
- 光速延迟导致跨地域数据传输存在30-150ms固有延迟,无法通过软件优化完全消除
- 半导体工艺逼近1nm极限,单芯片算力增长已从「每18个月翻倍」降至「每3-5年翻倍」
2)经济性天花板
- 维持99.99%可用性所需的冗余服务器成本是95%可用性的8-12倍
- 大模型单次推理能耗相当于传统搜索的50-100倍,能效比提升面临瓶颈
3)需求不可预测性
- 突发事件可能引发百倍流量暴增(如考试季/重大新闻),超出任何常规扩容预案
- 用户行为模式持续进化(如视频生成需求年增长300%),供给侧需持续追赶
3.3 长期演进趋势
1)阶段性改善
- 通过模型轻量化(如MoE架构)、芯片定制化(如TPU v5),2025年前有望将复杂任务处理成本降低60%
- 量子计算商业化后(预计2030+),特定类型计算任务可能实现指数级加速
2)持续存在领域
- 实时性要求极高的场景(如万人同时在线AI绘画)仍面临并发瓶颈
- 极端长尾需求(如百万token级文档分析)受硬件内存墙制约
3)用户体验演进
- 通过渐进式响应(先返回框架再填充细节)掩盖延迟感知
- 利用本地设备计算(如手机NPU)分流基础任务,形成混合计算范式
3.4 用户应对建议
1)认知层面
- 理解「服务降级」是分布式系统的固有特性,如同公路高峰拥堵无法完全避免
- 关注官方发布的服务等级协议(SLA),建立合理预期
2)技术层面
- 对关键业务集成重试策略+本地缓存(如指数退避重试算法)
- 优先使用结构化查询模板降低系统解析负担
结论
服务器繁忙问题将在10年内持续存在但显著缓解,其出现频率将从当前的「日常级」逐步过渡到「偶发型」,最终在量子计算+神经拟态芯片成熟后进入新平衡态。当前阶段的优化重点已从「消除问题」转向「智能降级与无缝恢复」,用户可通过技术适配获得接近连续可用的体验。