【玩转深度学习】手把手带你实战MNIST字体识别【LeNet网络】(PyTorch神经网络)

🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏:🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
目录
1. 前言
2. LeNet网络
2.1 LeNet——深度学习卷积神经网络结构的鼻祖
2.2 初始化数据
2.3 构建LeNet网络
2.4 参数优化器&&损失函数
2.5 训练函数
2.6 完整代码
3. 总结
1. 前言
- 👑《深度学习理论直觉三十讲》专栏持续更新中,未来最少文章数量为80篇。由于专栏刚刚建立,目前免费。后续将慢慢恢复原价至29.9🍉。
- 👑《深度学习理论直觉三十讲》专栏将分为三部分。第一部分是深度学习入门项目(回归、分类、预测等入门级项目;第二部分是深度学习大型实战项目(利用LSTM、CNN、RNN等技术实现时间预测、图像识别、手势识别等);第三部分是科研必学技能(PyTorch可视化、PyTorch模型迁移、PyTorch并行计算等)。
- 🔥每例项目都包括理论讲解、数据集、源代码。
正在更新中💹💹
🚨项目运行环境:
- 平台:Window11
- 语言环境:Python3.8
- 运行环境1:PyCharm 2021.3
- 运行环境2:Jupyter Notebook 7.3.2
- 框架:PyTorch 2.5.1(CUDA11.8)
2. LeNet网络
这一节中,我们尝试利用PyTorch构建卷积神经网络。这里以LeNet网络为例,利用MINST手写字体库进行训练,实现一个手写体的自动识别器。

2.1 LeNet——深度学习卷积神经网络结构的鼻祖
LeNet是1998年由YannLeCun提出的一种卷积神经网络,当时已经被美国大多数银行用于识别支票上的手写数字。详细资料可以浏览LeNet-5官网http://yann.lecun.com/exdb/lenet/,图3-43是LeNet进行手写体识别时,输人图片、各层特征图的可视化形式及其最终的识别结果。

LeNet-5的结构下图所示,其网络结构比较简单,如果不包括输入,它一共有7层,输入图像的大小为28×28。通过上一节的学习,我们可以分辨出C1层为6张特征图,由6个大小为5×5的卷积核过滤生成,特征图的尺寸为24×24。S2是池化层,采用最大池化法,池化窗口大小为2×2。因此,6张24×24的特征图池化后会生成6张12×12的池化特征图。C3层是卷积层,一共有16个过滤器,生成16张8×8大小的特征图,卷积核大小为5x5。这里,S2与C3的连接组合方式并不是固定的,C3层的每一张特征图可以连接S2层中的全部或者部分特征图。一般情况下,为了更好地降低总连接数,并不使用全部特征图的全连接方式。S4是池化层,它是由16张8×8的特征图最大池化生成的16张4x4的特征图,其池化核大小为2×2。F5是全连接层,一共有120个神经元节点,每个节点与S4层的16张池化特征图进行连接。因此,F5层与S4层是全连接。F6层有84个神经元节点,与F5进行全连接。最后一层为输出层,把输出的神经元节点数设为10,代表0到9的分值。
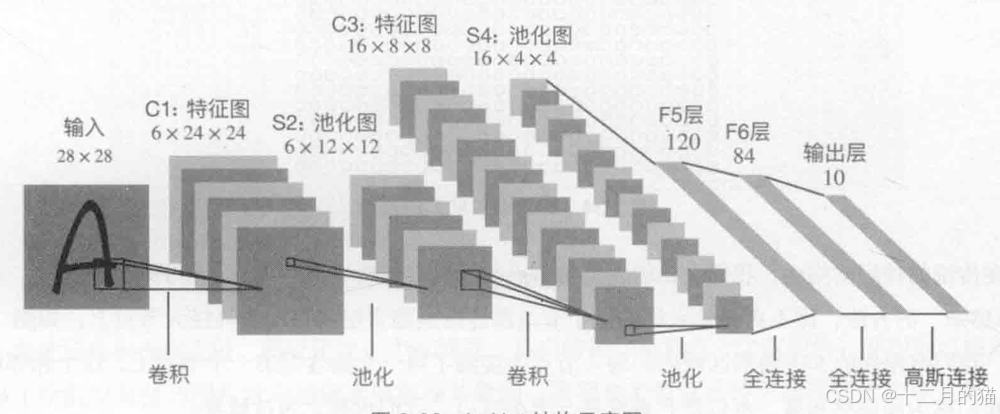
- 输入层
- 特征层:卷积层和激活层
- 池化层
- 全连接层
- 输出层
2.2 初始化数据
使用torchvision下载数据的过程:
- 导入torchvision的库
- 建立数据变换函数的实例transformer
- 用datasets.MNIST下载trainset和testset
- 用torch.utils.data.DataLoader加载trainset和testset
记忆:下载到代码中+加载到变量中
MNIST是一个手写数字数据库(官网地址:http://yann.lecun.com/exdb/mnist/)。如下图所示,该数据库有60000张训练样本和10000张测试样本,每张图的像素尺寸为28×28。其中train-images-idx3-ubyte.gz为训练样本集,train-labels-idx1-ubyte.gz为训练样本的标签集,tl0k-images-idx3-ubyte.gz为测试样本集,t10k-labels-idxl-ubyte.gz为测试样本的标签集。这些图片文件均被保存为二进制格式。

我们现在需要用到上述这些数据集。幸运的是,PyTorch为我们编写了快速下载并加载MNIST数据集的方法。为了方便图像的运用开发,PyTorch团队为我们专门编写了处理图像的工具包:torchvision。torchvision里面包含了图像加载、预处理等方法,还包括了数种经过预训练的经典卷积神经网络模型。
from torchvision import datasets, transforms # 图像加载和图像预处理
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]) # 多个数据变换集中到一起
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)代码解释:
1.
from torchvision import datasets, transforms这行代码从
torchvision库中导入了datasets和transforms两个模块:
datasets: 该模块提供了多个常用的数据集(如 MNIST、CIFAR 等),可以直接加载并进行训练和测试。transforms: 该模块提供了一系列图像预处理操作,如裁剪、旋转、标准化、转化为Tensor等,常用于数据增强和预处理。2.
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])这行代码定义了一个图像预处理操作:
transforms.Compose(): 该函数可以将多个图像变换操作组合成一个复合操作,它接收一个列表,其中可以包含多个预处理步骤。图像将按顺序应用这些步骤。在这里,
transform包含两个变换操作:
transforms.ToTensor(): 将图像从 PIL 图像格式或 numpy 数组转换为 PyTorch 的 Tensor 格式。这个转换会将图像的像素值范围从 [0, 255] 转换到 [0, 1]。transforms.Normalize((0.1307,), (0.3081,)): 对图像进行标准化处理。标准化操作会调整图像的均值和标准差,使其具有零均值和单位标准差。(0.1307,)是训练集的均值,(0.3081,)是标准差。它们是基于 MNIST 数据集的统计数据计算得出的。这两个变换将组合成一个处理流程,应用于图像数据。
3.
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)这行代码用于加载 MNIST 数据集的训练集:
datasets.MNIST: 这是torchvision.datasets提供的 MNIST 数据集的加载函数。它会自动下载 MNIST 数据集并将其加载到内存中。'data': 这是指定下载的 MNIST 数据集存储的目录。如果该目录不存在,torchvision会自动创建该目录并下载数据。train=True: 表示加载 MNIST 的训练集。如果是train=False,则加载测试集。download=True: 如果本地没有 MNIST 数据集,设置为True会自动从互联网上下载数据集。transform=transform: 指定在加载数据时应用的预处理操作。这里将之前定义的transform应用于图像。4.
testset = datasets.MNIST('data', train=False, download=True, transform=transform)这行代码用于加载 MNIST 数据集的测试集:
train=False: 表示加载 MNIST 的测试集。如果是train=True,则加载训练集。- 其他参数与
trainset中的解释相同。5. trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
torch.utils.data.DataLoader创建了一个数据加载器trainloader,用于从训练集trainset中加载数据。它设置了每个批次包含 4 个样本(batch_size=4),并且在每个训练周期(epoch)开始时对数据进行随机打乱(shuffle=True),以增加训练的多样性,减少过拟合的风险。同时,使用了 2 个子进程(num_workers=2)来并行加载数据,提高了数据加载的效率。
运行结果如下:
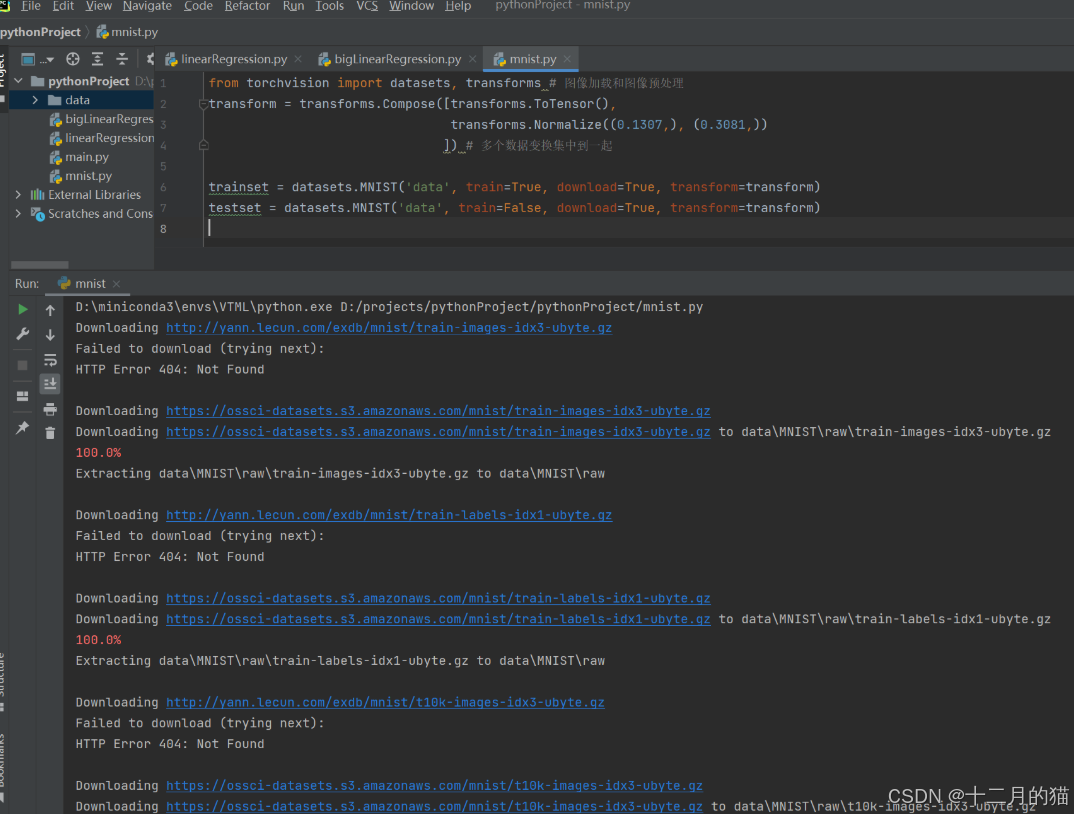
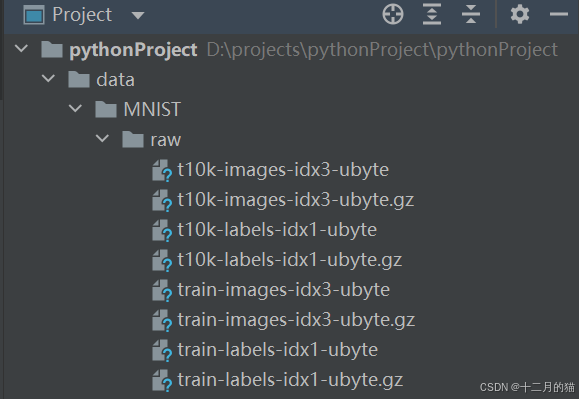
得到一个data文件夹,如下:
2.3 构建LeNet网络
先来看看LeNet网络结构:
准备好数据之后,我们可以开始构建LeNet模型。我们知道,初始化函数需要先运行父类的初始化函数。先定义C1卷积层,PyTorch中的nn.Conv2d()函数为我们简化了卷积层的构建。在C1层的定义中,第一个参数为1,代表输入1张灰度图;第二个参数为6,代表输出6张特征图;第三个参数是一个元组(5,5),也可以简化成5,代表大小为5×5的卷积核过滤器。然后定义C3卷积层,C3输入6张特征图,输出16张特征图,过滤器大小仍为5x5。接着定义全连接层,其中fc1是由池化层S4中的所有特征点(共16x4x4个)全连接到120个点,fc2是由120个点全连接到84个点,fc3是由84个点全连接到输出层中的10个输出节点。
池化层和激活层都属于不可学习参数的函数层,因此都放在forward函数中用nn.functional.F函数来调用,不属于网络层结构。
定义完初始函数之后,我们开始定义foward()函数。c1卷积之后,使用relu()函数增加了网络的非线性拟合能力,接着使用F.max_poo12d()函数对c1的特征图进行池化,池化核大小为2x2,也可以简化参数为2。经过两轮卷积和池化之后,使用view函数将x的形状转化成1维的向量,其中我们自定义了num_flat_features()函数来计算x的特征点的总数。在自定义得num_flat_features()函数中,由于PyTorch只接受批数据输人的方式(即同时输人好几张图片进行处理),所以我们在经过view()函数之前的x是4个维度的。假设我们批量输人4张图片,则x.size()的结果为(4,16,4,4)。我们使用x.size()[1:]返回x的第二维以后的形状,即(16,4,4)。因此,按照num_flat_features()函数返回的数值为16x4x4,即256,随后进行全连接fc1、fc2和fc3:
forward函数中需要添加上激活层、池化层等不需要学习的层结构。并且这些层结构都在nn.functional中。
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.c1 = nn.Conv2d(1,6,5) #输入28*28
self.c3 = nn.Conv2d(6,16,5) #输入12*12
self.fc1 = nn.Linear(16*4*4,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.c1(x)),2) #s2:池化层(输入24*24)
x = F.max_pool2d(F.relu(self.c3(x)),2) #s4:池化层(输入8*8)
x = x.view(-1,self.num_flat_features(x))
x = F.relu(self.fc1(x)) # 每个层处理后都要经过Relu层增加非线性成分
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self,x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
CUDA = torch.cuda.is_available()
if CUDA:
lenet = LeNet().cuda()
else:
lenet = LeNet()
2.4 参数优化器&&损失函数
损失函数:选择交叉熵损失函数作为损失函数
参数优化器:选用最基础的梯度下降SGD下降
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(lenet.parameters(),lr=0.001,momentum=0.9)2.5 训练函数
现在开始训练LeNet,我们将完全遍历训练数据2次。为了方便观察训练过程中损失值loss的
变化情况,定义变量running_loss。一开始,我们将running_loss设为0.0,随后对输入每一个训练
数据后的loss值进行累加,每训练1000次打印一次loss均值,并清零。enumerate(trainloader,0)表示从第0项开始对trainloader中的数据进行枚举,返回的i是序号,data是我们需要的数据,延迟其中包含了训练数据和标签。随后我们进行前向传播和反向传播。代码如下:
def train(model, criterion, optimizer, epochs=1):
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader,0):
inputs,labels = data
if CUDA:
inputs, labels = inputs.cuda(),labels.cuda()
outputs = model(inputs)
loss = criterion(ouputs, inputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if i%1000==999:
print(f'Epoch:{epoch+1}, Batch:{i+1}, Loss:{running_loss/1000}'
running_loss = 0.0
print('Finished Training')2.6 完整代码
深度学习项目基本框架:
- 准备数据集(定义训练的设备、训练集长度)
- 加载数据集
- 建立模型(模型包括网络模型和tensorboard模型)
- 确定损失函数
- 确定优化器
- 设置训练网络的一些参数
- 训练函数(每一轮包括 训练步骤 和 测试步骤)
- 主函数
import matplotlib
import os
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch import nn, optim
from torchvision import datasets, transforms
# 设置环境变量来避免重复加载错误
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
matplotlib.use('TkAgg')
# 1. 初始化数据
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=0)
# 2. 构建 LeNet 模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.c1 = nn.Conv2d(1, 6, 5) # 输入28x28
self.c3 = nn.Conv2d(6, 16, 5) # 输入12x12
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.c1(x)), 2) # 池化层(输入24x24)
x = F.max_pool2d(F.relu(self.c3(x)), 2) # 池化层(输入8x8)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
# 选择是否使用 GPU
CUDA = torch.cuda.is_available()
if CUDA:
lenet = LeNet().cuda()
else:
lenet = LeNet()
# 3. 选择优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(lenet.parameters(), lr=0.001, momentum=0.9)
# 4. 训练函数
def train(model, criterion, optimizer, epochs=1):
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
if CUDA:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs)
optimizer.zero_grad()
loss = criterion(outputs, labels) # 使用 labels 而不是 inputs
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999: # 每1000个batch打印一次
print(f'Epoch: {epoch + 1}, Batch: {i + 1}, Loss: {running_loss / 1000}')
running_loss = 0.0
print('Finished Training')
# 5. 主函数入口
if __name__ == '__main__':
train(lenet, criterion, optimizer, epochs=3)
运行结果如下:
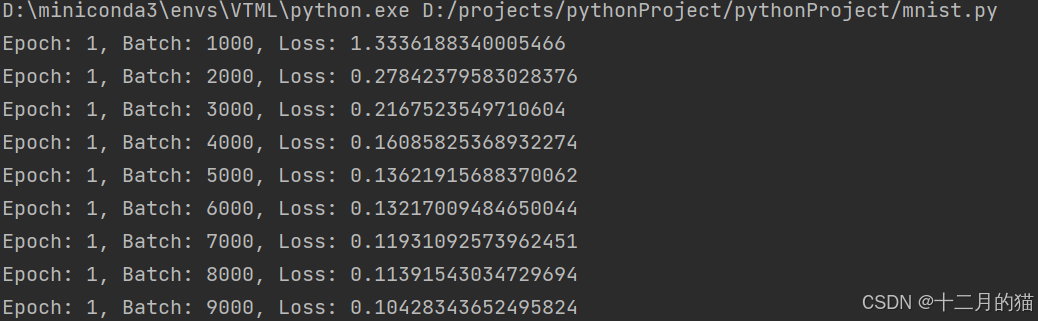
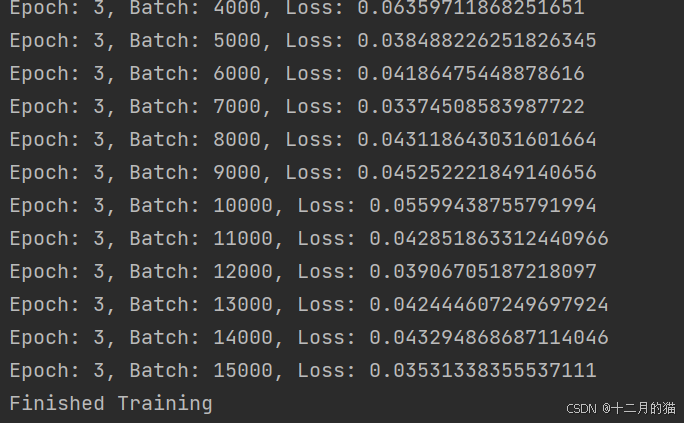
从结果中可以发现,训练是有效的,损失值loss的平均值从1.333降低为0.0353
3. 总结
如果想要学习更多深度学习知识,大家可以点个关注并订阅,持续学习、天天进步
你的点赞就是我更新的动力,如果觉得对你有帮助,辛苦友友点个赞,收个藏呀~~~