实操基于MCP驱动的 Agentic RAG:智能调度向量召回或者网络检索
我们展示了一个由 MCP 驱动的 Agentic RAG,它会搜索向量数据库,当然如果有需要他会自行进行网络搜索。
为了构建这个系统,我们将使用以下工具:
- 博查搜索 用于大规模抓取网络数据。
- 作为Faiss向量数据库。
- Cursor 作为 MCP 客户端。
以下是工作流程:

工作流程:
-
- 用户通过 MCP 客户端(Cursor)输入查询。
- 2-3客户端联系 MCP 服务器以选择相关工具。
- 4-6工具输出返回到客户端以生成响应。
环境准备
设置与安装
获取 BrightData API 密钥:
- 访问 Bright Data 并注册一个账户。
- 选择“代理与抓取”并创建一个新的“搜索引擎结果页面 (SERP) API”。
- 选择“原生代理访问”。
- 您将在那里找到您的用户名和密码。
- 将其存储在 .env 文件中。
- 国内最好还是利用国内的搜索引擎比如博查搜索

BRIGHDATA_USERNAME="..."
BRIGHDATA_PASSWORD="..."
安装依赖项:
确保您已安装 Python 3.11 或更高版本。
pip install mcp qdrant-client
运行项目
首先,按如下方式启动一个 Qdrant Docker 容器(确保您已下载 Docker):
docker run -p 6333:6333 -p 6334:6334
-v $(pwd)/qdrant_storage:/qdrant/storage:z
qdrant/qdrant
接下来,运行代码在向量数据库中创建一个集合。
配置MCP服务
最后,按如下方式设置您的本地 MCP 服务器:
- 转到 Cursor 设置。
- 选择 MCP。
- 添加新的全局 MCP 服务器。
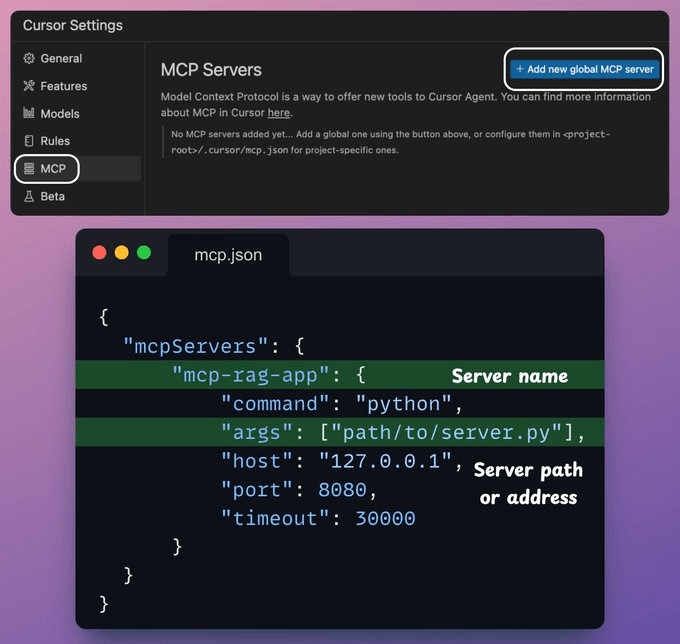
在 JSON 文件中添加以下内容:
{
"mcpServers": {
"mcp-rag-app": {
"command": "python",
"args": ["/absolute/path/to/server.py"],
"host": "127.0.0.1",
"port": 8080,
"timeout": 30000
}
}
}
完成!您现在可以与向量数据库进行交互,并在需要时使用网络搜索作为后备方案。
本文将提供的完整的源代码工大家参考练习。
让我们开始实现吧!
1.启动一个 MCP 服务器
首先,我们定义一个带有主机 URL 和端口的 MCP 服务器。

2.向量数据库 MCP 工具
通过 MCP 服务器暴露的工具有两个要求:
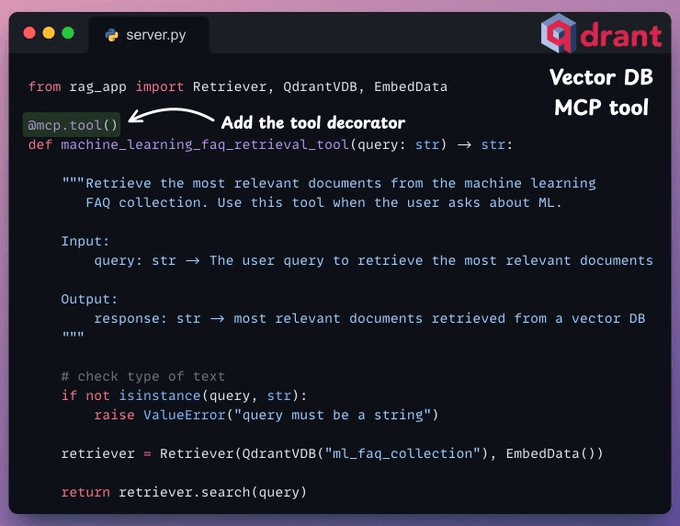
- 必须使用“tool”装饰器进行装饰。
- 必须有清晰的文档字符串。
在下面的代码中,我们有一个用于查询向量数据库的 MCP 工具。它存储了与机器学习相关的常见问题解答。
3.网络搜索 MCP 工具
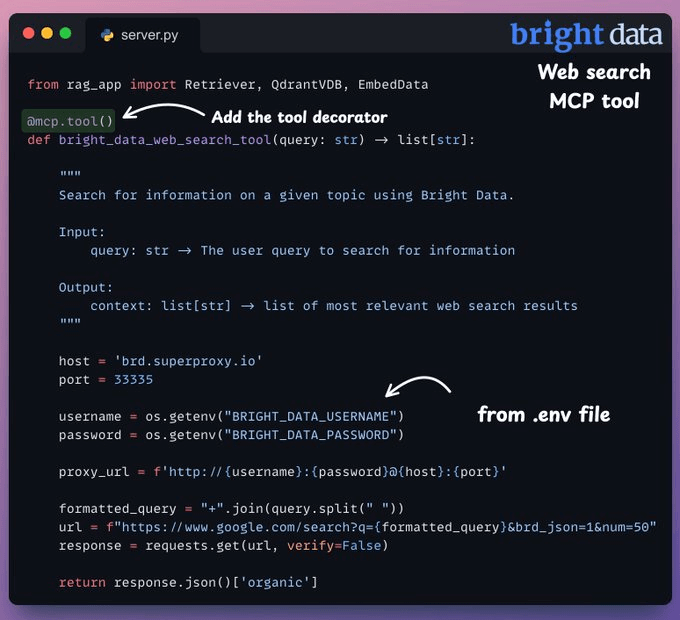
如果查询与机器学习无关,我们需要一个回退机制。
因此,我们使用 Bright Data 的 SERP API 进行网络搜索,以从多个来源抓取数据,获取相关上下文。
4.将 MCP 服务器与 Cursor 集成
在我们的设置中,Cursor 是一个使用 MCP 服务器暴露的工具的 MCP 客户端。
要集成 MCP 服务器,请转到设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下内容👇
搞定啦!你的本地 MCP 服务器已经启动并且与 Cursor 连接成功🚀!
它有两个 MCP 工具:

- Bright Data 网络搜索工具,用于大规模抓取数据。
- 向量数据库搜索工具,用于查询相关文档。
接下来,我们与 MCP 服务器进行交互。

- 当我们提出与机器学习相关的查询时,它会调用向量数据库工具。这是一个标准RAG召回。
- 但是当我们提出一个通用查询时,它会调用 博查搜索 网络搜索工具,从多个来源收集网络数据。
当代理使用工具时,它们会遇到诸如 IP 封锁、机器人流量、验证码破解等问题。这些问题会阻碍代理的执行。
为了解决这个问题,我们在这个演示中使用了 博查搜索。
它可以让您:
- 在不被封锁的情况下为代理大规模抓取数据。
- 使用高级浏览器工具模拟用户行为。
- 使用实时和历史网络数据构建代理应用程序。
详细代码
server.py
# server.py
from mcp.server.fastmcp import FastMCP
from rag_code import *
# Create an MCP server
mcp = FastMCP("MCP-RAG-app",
host="127.0.0.1",
port=8080,
timeout=30)
@mcp.tool()
def machine_learning_faq_retrieval_tool(query: str) -> str:
"""Retrieve the most relevant documents from the machine learning
FAQ collection. Use this tool when the user asks about ML.
Input:
query: str -> The user query to retrieve the most relevant documents
Output:
context: str -> most relevant documents retrieved from a vector DB
"""
# check type of text
if not isinstance(query, str):
raise ValueError("query must be a string")
retriever = Retriever(QdrantVDB("ml_faq_collection"), EmbedData())
response = retriever.search(query)
return response
@mcp.tool()
def bright_data_web_search_tool(query: str) -> list[str]:
"""
Search for information on a given topic using Bright Data.
Use this tool when the user asks about a specific topic or question
that is not related to general machine learning.
Input:
query: str -> The user query to search for information
Output:
context: list[str] -> list of most relevant web search results
"""
# check type of text
if not isinstance(query, str):
raise ValueError("query must be a string")
import os
import requests
import json
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# 博查搜索 API 配置
url = "https://api.bochaai.com/v1/web-search"
api_key = os.getenv("BOCHAAI_API_KEY")
if not api_key:
raise ValueError("请在 .env 文件中设置 BOCHAAI_API_KEY")
payload = json.dumps({
"query": query,
"summary": True,
"count": 10,
"page": 1
})
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
# Return organic search results
return response.json()['organic']
if __name__ == "__main__":
print("Starting MCP server at http://127.0.0.1:8080 on port 8080")
mcp.run()
rag.py
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from tqdm import tqdm
from fasiimcp import FasiClient, FasiConfig
faq_text = """Question 1: What is the first step before building a machine learning model?
Answer 1: Understand the problem, define the objective, and identify the right metrics for evaluation.
Question 2: How important is data cleaning in ML?
Answer 2: Extremely important. Clean data improves model performance and reduces the chance of misleading results.
Question 3: Should I normalize or standardize my data?
Answer 3: Yes, especially for models sensitive to feature scales like SVMs, KNN, and neural networks.
Question 4: When should I use feature engineering?
Answer 4: Always consider it. Well-crafted features often yield better results than complex models.
Question 5: How to handle missing values?
Answer 5: Use imputation techniques like mean/median imputation, or model-based imputation depending on the context.
Question 6: Should I balance my dataset for classification tasks?
Answer 6: Yes, especially if the classes are imbalanced. Techniques include resampling, SMOTE, and class-weighting.
Question 7: How do I select features for my model?
Answer 7: Use domain knowledge, correlation analysis, or techniques like Recursive Feature Elimination or SHAP values.
Question 8: Is it good to use all features available?
Answer 8: Not always. Irrelevant or redundant features can reduce performance and increase overfitting.
Question 9: How do I avoid overfitting?
Answer 9: Use techniques like cross-validation, regularization, pruning (for trees), and dropout (for neural nets).
Question 10: Why is cross-validation important?
Answer 10: It provides a more reliable estimate of model performance by reducing bias from a single train-test split.
Question 11: What’s a good train-test split ratio?
Answer 11: Common ratios are 80/20 or 70/30, but use cross-validation for more robust evaluation.
Question 12: Should I tune hyperparameters?
Answer 12: Yes. Use grid search, random search, or Bayesian optimization to improve model performance.
Question 13: What’s the difference between training and validation sets?
Answer 13: Training set trains the model, validation set tunes hyperparameters, and test set evaluates final performance.
Question 14: How do I know if my model is underfitting?
Answer 14: It performs poorly on both training and test sets, indicating it hasn’t learned patterns well.
Question 15: What are signs of overfitting?
Answer 15: High accuracy on training data but poor generalization to test or validation data.
Question 16: Is ensemble modeling useful?
Answer 16: Yes. Ensembles like Random Forests or Gradient Boosting often outperform individual models.
Question 17: When should I use deep learning?
Answer 17: Use it when you have large datasets, complex patterns, or tasks like image and text processing.
Question 18: What is data leakage and how to avoid it?
Answer 18: Data leakage is using future or target-related information during training. Avoid by carefully splitting and preprocessing.
Question 19: How do I measure model performance?
Answer 19: Choose appropriate metrics: accuracy, precision, recall, F1, ROC-AUC for classification; RMSE, MAE for regression.
Question 20: Why is model interpretability important?
Answer 20: It builds trust, helps debug, and ensures compliance—especially important in high-stakes domains like healthcare.
"""
new_faq_text = [i.replace("
", " ") for i in faq_text.split("
")]
def batch_iterate(lst, batch_size):
for i in range(0, len(lst), batch_size):
yield lst[i : i + batch_size]
class EmbedData:
def __init__(self,
embed_model_name="nomic-ai/nomic-embed-text-v1.5",
batch_size=32):
self.embed_model_name = embed_model_name
self.embed_model = self._load_embed_model()
self.batch_size = batch_size
self.embeddings = []
def _load_embed_model(self):
embed_model = HuggingFaceEmbedding(model_name=self.embed_model_name,
trust_remote_code=True,
cache_folder='./hf_cache'
)
return embed_model
def generate_embedding(self, context):
return self.embed_model.get_text_embedding_batch(context)
def embed(self, contexts):
self.contexts = contexts
for batch_context in tqdm(batch_iterate(contexts, self.batch_size),
total=len(contexts)//self.batch_size,
desc="Embedding data in batches"):
batch_embeddings = self.generate_embedding(batch_context)
self.embeddings.extend(batch_embeddings)
class FasiiVDB:
def __init__(self, collection_name, vector_dim=768, batch_size=512):
self.collection_name = collection_name
self.batch_size = batch_size
self.vector_dim = vector_dim
self.config = FasiConfig(url="http://localhost:6333")
self.client = FasiClient(self.config)
def create_collection(self):
if not self.client.collection_exists(self.collection_name):
self.client.create_collection(self.collection_name, self.vector_dim)
def ingest_data(self, embeddata):
for batch_context, batch_embeddings in tqdm(zip(batch_iterate(embeddata.contexts, self.batch_size),
batch_iterate(embeddata.embeddings, self.batch_size)),
total=len(embeddata.contexts)//self.batch_size,
desc="Ingesting in batches"):
self.client.upload_vectors(self.collection_name, batch_embeddings, [{"context": context} for context in batch_context])
class Retriever:
def __init__(self, vector_db, embeddata):
self.vector_db = vector_db
self.embeddata = embeddata
def search(self, query):
query_embedding = self.embeddata.embed_model.get_query_embedding(query)
# select the top 3 results
result = self.vector_db.client.search(
collection_name=self.vector_db.collection_name,
query_vector=query_embedding,
limit=3
)
combined_prompt = [item["payload"]["context"] for item in result]
final_output = "
---
".join(combined_prompt)
return final_output
应该还想了解
各种构建RAG 系统的技术
在纸上,实现一个 RAG 系统似乎很简单——连接一个向量数据库,处理文档,嵌入数据,嵌入查询,查询向量数据库,然后提示 LLM。

但在实践中,将原型转化为高性能应用程序是一个完全不同的挑战。
我之前发布了一个两个专栏,涵盖了 各种实用技术来构建现实世界的 RAG 系统:
- 阅读第一部分 →基于python从零实现各类RAG
- 阅读第二部分 →LlamaIndex实战
本文地址:https://www.vps345.com/2568.html