【笔记】linux 本地部署deepseek大模型(离线版)
环境:Ubuntu14.04.3
工具:ollama
一、配置Ollama
1)在有网电脑上访问https://ollama.com/download/ollama-linux-amd64.tgz下载ollama的Linux压缩包,然后将压缩包复制到用户目录下。
2) 在安装包同一目录下,将文末install.sh文件添加进去。该文件进行了软件的安装,服务配置,环境变量配置,开机自启相关操作。
3) 运行安装
chmod +x install.sh #给脚本赋予执行权限
./install.sh
#如果报错误:bash: ./build_android.sh:/bin/sh^M:解释器错误: 没有那个文件或目录,执行下面命令后,再执行./install.sh命令
sed -i 's/ $//' install.sh
4) 配置Ollama远程访问
Ollama服务启动后,默认只可本地访问,访问地址:http:127.0.0.1:11434想要实现外部访问需要修改其配置文件。
vim /etc/systemd/system/ollama.service 写入以下内容
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434" #设置OLLAMA_HOST=0.0.0.0环境变量,从而允许远程访问。
Environment="CUDA_VISIBLE_DEVICES=3,2" #多GPU 管理
Environment="OLLAMA_MODELS=/data/ollama/model" #设置模型路径
[Install]
WantedBy=default.target
5) 修改之后更新服务并重启
sudo systemctl daemon-reload
sudo systemctl restart ollama
#这里会因系统版本不同提示没有相关指令,离线情况下无法下载,遇到这种情况可查看对应环境版本解决问题也可在命令行单独运行命令,如:exprot OLLAMA_HOST=0.0.0.0:11434
6) 修改model文件夹权限
sudo chmod 777 /data/ollama/model
7) 验证Ollama服务是否正常运行
运行以下命令,确保Ollama服务正在监听所有网络接口:命令语法:
sudo netstat -tulpn | grep ollama
测试远程访问
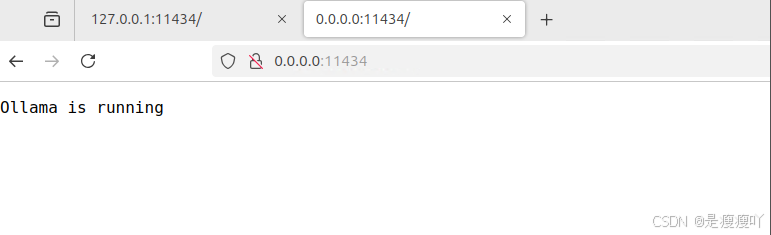
此时在浏览器中访问:http://0.0.0.0:11434出现如下页面即说明服务启动成功。
二、gguf下载及配置
1)从Huggingface下载GGUF文件 (需要在联网机上进行下载)
Huggingface是一个开放的人工智能模型库,提供了大量经过预训练的模型供用户下载和使用。要下载Llama模型的GGUF文件,请按照以下步骤操作:
(1)访问Huggingface网站: https://huggingface.co/models。
(2) 搜索GGUF模型:在搜索框中输入“deepseek gguf”或相关关键词。当前在huggingface上总共有以下几种参数的deepseek R1:
DeepSeek-R1 671B
DeepSeek-R1-Zero 671B
DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1-Distill-Qwen-32B
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-R1-Distill-Llama-8B
DeepSeek-R1-Distill-Qwen-7B
DeepSeek-R1-Distill-Qwen-1.5B
选择GGUF文件:在模型页面中,找到Files and versions栏,选择你想要下载的GGUF文件版本。通常,不同版本的GGUF文件大小不同,对应着不同的模型效果和精度。如何选择版本:
GGUF文件名中的量化标识(例如Q4_K_M、Q5_K_S等)代表不同的量化方法:
Q2 / Q3 / Q4 / Q5 / Q6 / Q8: 量化的比特数(如Q4表示4-bit量化)。
K: 表示量化时使用了特殊的优化方法(如分组量化)。
后缀字母:表示量化子类型:
S (Small): 更小的模型体积,但性能损失稍大。
M (Medium): 平衡体积和性能。
L (Large): 保留更多精度,体积较大。
常见量化版本对比:

a.资源有限(如低显存GPU/CPU):选择低比特量化(如Q4_K_M或Q3_K_S),牺牲少量精度换取更低的显存占用。
b.平衡性能与速度:推荐Q4_K_M或Q5_K_S,适合大多数场景。
c.追求最高质量:选择Q5_K_M或Q6_K,接近原始模型效果,但需要更多资源。
d.完全无损推理:使用Q8_0(8-bit量化),但体积最大。
(3)下载GGUF文件:点击下载按钮,将GGUF文件保存。注意事项:
a.大模型文件(如7B参数的GGUF文件)体积较大(可能超过10GB),直接存储或传输可能不便,将单一大文件分割为多个小文件(例如拆分成9个分片),每个分片包含模型的一部分数据。必须下载全部9个文件(从00001到00009),并确保它们位于同一目录下。
b.量化与性能关系:量化级别越低,模型回答的连贯性和逻辑性可能下降,尤其在复杂任务中(如代码生成、数学推理)。
c.硬件兼容性:
d.低量化模型(如Q2/Q3)更适合纯CPU推理。
e.高量化模型(如Q5/Q6)在GPU上表现更好。
建议对不同量化版本进行实际测试,选择最适合你硬件和任务的版本。
2)配置模型
(1)在/data/ollama/model下面新建一个模型名称文件夹(model为模型名称文件夹)
(2)把下载的gguf文件移进去,这里根据本机配置下载的是DeepSeek-R1-Distill-Qwen-1.5B-Q8_0.gguf
(3)新建一个Modelfile空白文件,指定GGUF模型文件的路径
FROM ./path/to/your-model.gguf
(4)创建Ollama模型:打开终端或命令行界面,运行以下命令来创建Ollama模型:
ollama create my_llama_model -f Modelfile
my_llama_model是为模型指定的名称,-f选项后面跟的是Modelfile文件的路径。
(5)检查模型是否创建成功
ollama list
(6)Ollama已经下载安装完成,执行以下命令启动服务
ollama serve
(7)查看Ollama服务是否成功启动
ollama -v
(8)运行模型:一旦模型创建成功,可以使用以下命令来运行:
ollama run my_llama_model
三、可视化页面 --Chatbox
在有网电脑上访问https://chatboxai.app/zh下载Chatbox AI,安装在需要的客户端机上,完成后进行如下设置,便可以开启聊天窗口了

install.sh
#!/bin/sh
# This script installs Ollama on Linux.
# It detects the current operating system architecture and installs the appropriate version of Ollama.
set -eu
status() { echo ">>> $*" >&2; }
error() { echo "ERROR $*"; exit 1; }
warning() { echo "WARNING: $*"; }
TEMP_DIR=$(mktemp -d)
cleanup() { rm -rf $TEMP_DIR; }
trap cleanup EXIT
available() { command -v $1 >/dev/null; }
require() {
local MISSING=''
for TOOL in $*; do
if ! available $TOOL; then
MISSING="$MISSING $TOOL"
fi
done
echo $MISSING
}
[ "$(uname -s)" = "Linux" ] || error 'This script is intended to run on Linux only.'
ARCH=$(uname -m)
case "$ARCH" in
x86_64) ARCH="amd64" ;;
aarch64|arm64) ARCH="arm64" ;;
*) error "Unsupported architecture: $ARCH" ;;
esac
IS_WSL2=false
KERN=$(uname -r)
case "$KERN" in
*icrosoft*WSL2 | *icrosoft*wsl2) IS_WSL2=true;;
*icrosoft) error "Microsoft WSL1 is not currently supported. Please use WSL2 with 'wsl --set-version 2'" ;;
*) ;;
esac
VER_PARAM="${OLLAMA_VERSION:+?version=$OLLAMA_VERSION}"
SUDO=
if [ "$(id -u)" -ne 0 ]; then
# Running as root, no need for sudo
if ! available sudo; then
error "This script requires superuser permissions. Please re-run as root."
fi
SUDO="sudo"
fi
NEEDS=$(require curl awk grep sed tee xargs)
if [ -n "$NEEDS" ]; then
status "ERROR: The following tools are required but missing:"
for NEED in $NEEDS; do
echo " - $NEED"
done
exit 1
fi
for BINDIR in /usr/local/bin /usr/bin /bin; do
echo $PATH | grep -q $BINDIR && break || continue
done
OLLAMA_INSTALL_DIR=$(dirname ${BINDIR})
status "Installing ollama to $OLLAMA_INSTALL_DIR"
$SUDO install -o0 -g0 -m755 -d $BINDIR
$SUDO install -o0 -g0 -m755 -d "$OLLAMA_INSTALL_DIR"
#if curl -I --silent --fail --location "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" >/dev/null ; then
#注释掉以下代码
# status "Downloading Linux ${ARCH} bundle"
# curl --fail --show-error --location --progress-bar
# "https://ollama.com/download/ollama-linux-${ARCH}.tgz${VER_PARAM}" |
# $SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
# BUNDLE=1
# if [ "$OLLAMA_INSTALL_DIR/bin/ollama" != "$BINDIR/ollama" ] ; then
# status "Making ollama accessible in the PATH in $BINDIR"
# $SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
# fi
#else
# status "Downloading Linux ${ARCH} CLI"
# curl --fail --show-error --location --progress-bar -o "$TEMP_DIR/ollama"
# "https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}"
# $SUDO install -o0 -g0 -m755 $TEMP_DIR/ollama $OLLAMA_INSTALL_DIR/ollama
# BUNDLE=0
# if [ "$OLLAMA_INSTALL_DIR/ollama" != "$BINDIR/ollama" ] ; then
# status "Making ollama accessible in the PATH in $BINDIR"
# $SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
# fi
#fi
#新增以下代码
LOCAL_OLLAMA_TGZ="./ollama-linux-${ARCH}.tgz${VER_PARAM}"
if [ -f "$LOCAL_OLLAMA_TGZ" ]; then
status "Installing from local file $LOCAL_OLLAMA_TGZ"
$SUDO tar -xzf "$LOCAL_OLLAMA_TGZ" -C "$OLLAMA_INSTALL_DIR"
BUNDLE=1
if [ ! -e "$BINDIR/ollama" ]; then
status "Making ollama accessible in the PATH in $BINDIR"
$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi
else
echo "Error: The local file $LOCAL_OLLAMA_TGZ does not exist."
exit 1
fi
install_success() {
status 'The Ollama API is now available at 127.0.0.1:11434.'
status 'Install complete. Run "ollama" from the command line.'
}
trap install_success EXIT
# Everything from this point onwards is optional.
configure_systemd() {
if ! id ollama >/dev/null 2>&1; then
status "Creating ollama user..."
$SUDO useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
fi
if getent group render >/dev/null 2>&1; then
status "Adding ollama user to render group..."
$SUDO usermod -a -G render ollama
fi
if getent group video >/dev/null 2>&1; then
status "Adding ollama user to video group..."
$SUDO usermod -a -G video ollama
fi
status "Adding current user to ollama group..."
$SUDO usermod -a -G ollama $(whoami)
status "Creating ollama systemd service..."
cat </dev/null
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=$BINDIR/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
EOF
SYSTEMCTL_RUNNING="$(systemctl is-system-running || true)"
case $SYSTEMCTL_RUNNING in
running|degraded)
status "Enabling and starting ollama service..."
$SUDO systemctl daemon-reload
$SUDO systemctl enable ollama
start_service() { $SUDO systemctl restart ollama; }
trap start_service EXIT
;;
esac
}
if available systemctl; then
configure_systemd
fi
# WSL2 only supports GPUs via nvidia passthrough
# so check for nvidia-smi to determine if GPU is available
if [ "$IS_WSL2" = true ]; then
if available nvidia-smi && [ -n "$(nvidia-smi | grep -o "CUDA Version: [0-9]*.[0-9]*")" ]; then
status "Nvidia GPU detected."
fi
install_success
exit 0
fi
# Install GPU dependencies on Linux
if ! available lspci && ! available lshw; then
warning "Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies."
exit 0
fi
check_gpu() {
# Look for devices based on vendor ID for NVIDIA and AMD
case $1 in
lspci)
case $2 in
nvidia) available lspci && lspci -d '10de:' | grep -q 'NVIDIA' || return 1 ;;
amdgpu) available lspci && lspci -d '1002:' | grep -q 'AMD' || return 1 ;;
esac ;;
lshw)
case $2 in
nvidia) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* [10DE]' || return 1 ;;
amdgpu) available lshw && $SUDO lshw -c display -numeric -disable network | grep -q 'vendor: .* [1002]' || return 1 ;;
esac ;;
nvidia-smi) available nvidia-smi || return 1 ;;
esac
}
if check_gpu nvidia-smi; then
status "NVIDIA GPU installed."
exit 0
fi
if ! check_gpu lspci nvidia && ! check_gpu lshw nvidia && ! check_gpu lspci amdgpu && ! check_gpu lshw amdgpu; then
install_success
warning "No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode."
exit 0
fi
if check_gpu lspci amdgpu || check_gpu lshw amdgpu; then
if [ $BUNDLE -ne 0 ]; then
status "Downloading Linux ROCm ${ARCH} bundle"
curl --fail --show-error --location --progress-bar
"https://ollama.com/download/ollama-linux-${ARCH}-rocm.tgz${VER_PARAM}" |
$SUDO tar -xzf - -C "$OLLAMA_INSTALL_DIR"
install_success
status "AMD GPU ready."
exit 0
fi
# Look for pre-existing ROCm v6 before downloading the dependencies
for search in "${HIP_PATH:-''}" "${ROCM_PATH:-''}" "/opt/rocm" "/usr/lib64"; do
if [ -n "${search}" ] && [ -e "${search}/libhipblas.so.2" -o -e "${search}/lib/libhipblas.so.2" ]; then
status "Compatible AMD GPU ROCm library detected at ${search}"
install_success
exit 0
fi
done
status "Downloading AMD GPU dependencies..."
$SUDO rm -rf /usr/share/ollama/lib
$SUDO chmod o+x /usr/share/ollama
$SUDO install -o ollama -g ollama -m 755 -d /usr/share/ollama/lib/rocm
curl --fail --show-error --location --progress-bar "https://ollama.com/download/ollama-linux-amd64-rocm.tgz${VER_PARAM}"
| $SUDO tar zx --owner ollama --group ollama -C /usr/share/ollama/lib/rocm .
install_success
status "AMD GPU ready."
exit 0
fi
CUDA_REPO_ERR_MSG="NVIDIA GPU detected, but your OS and Architecture are not supported by NVIDIA. Please install the CUDA driver manually https://docs.nvidia.com/cuda/cuda-installation-guide-linux/"
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-7-centos-7
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-8-rocky-8
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#rhel-9-rocky-9
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#fedora
install_cuda_driver_yum() {
status 'Installing NVIDIA repository...'
case $PACKAGE_MANAGER in
yum)
$SUDO $PACKAGE_MANAGER -y install yum-utils
if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then
$SUDO $PACKAGE_MANAGER-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo
else
error $CUDA_REPO_ERR_MSG
fi
;;
dnf)
if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo" >/dev/null ; then
$SUDO $PACKAGE_MANAGER config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-$1$2.repo
else
error $CUDA_REPO_ERR_MSG
fi
;;
esac
case $1 in
rhel)
status 'Installing EPEL repository...'
# EPEL is required for third-party dependencies such as dkms and libvdpau
$SUDO $PACKAGE_MANAGER -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-$2.noarch.rpm || true
;;
esac
status 'Installing CUDA driver...'
if [ "$1" = 'centos' ] || [ "$1$2" = 'rhel7' ]; then
$SUDO $PACKAGE_MANAGER -y install nvidia-driver-latest-dkms
fi
$SUDO $PACKAGE_MANAGER -y install cuda-drivers
}
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#ubuntu
# ref: https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#debian
install_cuda_driver_apt() {
status 'Installing NVIDIA repository...'
if curl -I --silent --fail --location "https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.deb" >/dev/null ; then
curl -fsSL -o $TEMP_DIR/cuda-keyring.deb https://developer.download.nvidia.com/compute/cuda/repos/$1$2/$(uname -m | sed -e 's/aarch64/sbsa/')/cuda-keyring_1.1-1_all.deb
else
error $CUDA_REPO_ERR_MSG
fi
case $1 in
debian)
status 'Enabling contrib sources...'
$SUDO sed 's/main/contrib/' < /etc/apt/sources.list | $SUDO tee /etc/apt/sources.list.d/contrib.list > /dev/null
if [ -f "/etc/apt/sources.list.d/debian.sources" ]; then
$SUDO sed 's/main/contrib/' < /etc/apt/sources.list.d/debian.sources | $SUDO tee /etc/apt/sources.list.d/contrib.sources > /dev/null
fi
;;
esac
status 'Installing CUDA driver...'
$SUDO dpkg -i $TEMP_DIR/cuda-keyring.deb
$SUDO apt-get update
[ -n "$SUDO" ] && SUDO_E="$SUDO -E" || SUDO_E=
DEBIAN_FRONTEND=noninteractive $SUDO_E apt-get -y install cuda-drivers -q
}
if [ ! -f "/etc/os-release" ]; then
error "Unknown distribution. Skipping CUDA installation."
fi
. /etc/os-release
OS_NAME=$ID
OS_VERSION=$VERSION_ID
PACKAGE_MANAGER=
for PACKAGE_MANAGER in dnf yum apt-get; do
if available $PACKAGE_MANAGER; then
break
fi
done
if [ -z "$PACKAGE_MANAGER" ]; then
error "Unknown package manager. Skipping CUDA installation."
fi
if ! check_gpu nvidia-smi || [ -z "$(nvidia-smi | grep -o "CUDA Version: [0-9]*.[0-9]*")" ]; then
case $OS_NAME in
centos|rhel) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -d '.' -f 1) ;;
rocky) install_cuda_driver_yum 'rhel' $(echo $OS_VERSION | cut -c1) ;;
fedora) [ $OS_VERSION -lt '39' ] && install_cuda_driver_yum $OS_NAME $OS_VERSION || install_cuda_driver_yum $OS_NAME '39';;
amzn) install_cuda_driver_yum 'fedora' '37' ;;
debian) install_cuda_driver_apt $OS_NAME $OS_VERSION ;;
ubuntu) install_cuda_driver_apt $OS_NAME $(echo $OS_VERSION | sed 's/.//') ;;
*) exit ;;
esac
fi
if ! lsmod | grep -q nvidia || ! lsmod | grep -q nvidia_uvm; then
KERNEL_RELEASE="$(uname -r)"
case $OS_NAME in
rocky) $SUDO $PACKAGE_MANAGER -y install kernel-devel kernel-headers ;;
centos|rhel|amzn) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE kernel-headers-$KERNEL_RELEASE ;;
fedora) $SUDO $PACKAGE_MANAGER -y install kernel-devel-$KERNEL_RELEASE ;;
debian|ubuntu) $SUDO apt-get -y install linux-headers-$KERNEL_RELEASE ;;
*) exit ;;
esac
NVIDIA_CUDA_VERSION=$($SUDO dkms status | awk -F: '/added/ { print $1 }')
if [ -n "$NVIDIA_CUDA_VERSION" ]; then
$SUDO dkms install $NVIDIA_CUDA_VERSION
fi
if lsmod | grep -q nouveau; then
status 'Reboot to complete NVIDIA CUDA driver install.'
exit 0
fi
$SUDO modprobe nvidia
$SUDO modprobe nvidia_uvm
fi
# make sure the NVIDIA modules are loaded on boot with nvidia-persistenced
if available nvidia-persistenced; then
$SUDO touch /etc/modules-load.d/nvidia.conf
MODULES="nvidia nvidia-uvm"
for MODULE in $MODULES; do
if ! grep -qxF "$MODULE" /etc/modules-load.d/nvidia.conf; then
echo "$MODULE" | $SUDO tee -a /etc/modules-load.d/nvidia.conf > /dev/null
fi
done
fi
status "NVIDIA GPU ready."
install_success 参考:DeepSeek-R1本地部署实践_deepseek-r1-gguf-CSDN博客