【深度学习项目】语义分割-DeepLab网络(DeepLabV3介绍、基于Pytorch实现DeepLabV3网络)
文章目录
- 介绍
- 深度学习语义分割的关键特点
- 主要架构和技术
- 数据集和评价指标
- 总结
- DeepLab
- DeepLab 的核心技术
- DeepLab 的发展历史
- DeepLab V3
- 网络结构
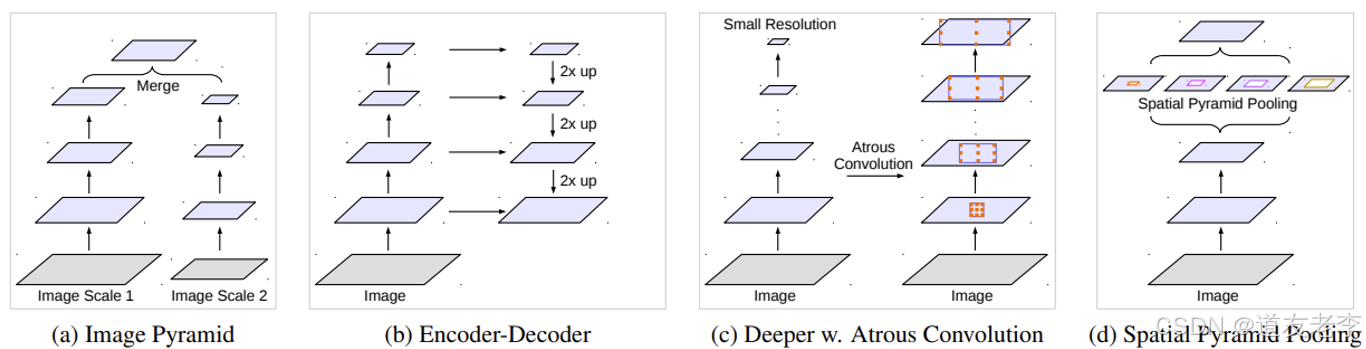
- 获取多尺度信息架构
- Cascade Model
- ASPP Model
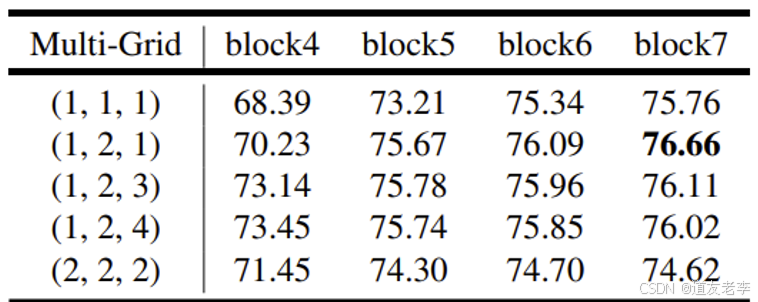
- Multi-Grid
- Pytorch官方实现的DeepLab V3
- 该项目主要是来自pytorch官方torchvision模块中的源码
- 环境配置
- 文件结构
- 预训练权重下载地址
- 数据集,本项目使用的是PASCAL VOC2012数据集
- 训练方法
- 注意事项
- 实现代码
- src文件目录
- train_utils文件目录
- 根目录
个人主页:道友老李
欢迎加入社区:道友老李的学习社区
介绍
深度学习语义分割(Semantic Segmentation)是一种计算机视觉任务,它旨在将图像中的每个像素分类为预定义类别之一。与物体检测不同,后者通常只识别和定位图像中的目标对象边界框,语义分割要求对图像的每一个像素进行分类,以实现更精细的理解。这项技术在自动驾驶、医学影像分析、机器人视觉等领域有着广泛的应用。
深度学习语义分割的关键特点
- 像素级分类:对于输入图像的每一个像素点,模型都需要预测其属于哪个类别。
- 全局上下文理解:为了正确地分割复杂场景,模型需要考虑整个图像的内容及其上下文信息。
- 多尺度处理:由于目标可能出现在不同的尺度上,有效的语义分割方法通常会处理多种分辨率下的特征。
主要架构和技术
-
全卷积网络 (FCN):
- FCN是最早的端到端训练的语义分割模型之一,它移除了传统CNN中的全连接层,并用卷积层替代,从而能够接受任意大小的输入并输出相同空间维度的概率图。
-
跳跃连接 (Skip Connections):
- 为了更好地保留原始图像的空间细节,一些模型引入了跳跃连接,即从编码器部分直接传递特征到解码器部分,这有助于恢复细粒度的结构信息。
-
U-Net:
- U-Net是一个专为生物医学图像分割设计的网络架构,它使用了对称的收缩路径(下采样)和扩展路径(上采样),以及丰富的跳跃连接来捕捉局部和全局信息。
-
DeepLab系列:
- DeepLab采用了空洞/膨胀卷积(Atrous Convolution)来增加感受野而不减少特征图分辨率,并通过多尺度推理和ASPP模块(Atrous Spatial Pyramid Pooling)增强了对不同尺度物体的捕捉能力。
-
PSPNet (Pyramid Scene Parsing Network):
- PSPNet利用金字塔池化机制收集不同尺度的上下文信息,然后将其融合用于最终的预测。
-
RefineNet:
- RefineNet强调了高分辨率特征的重要性,并通过一系列细化单元逐步恢复细节,确保输出高质量的分割结果。
-
HRNet (High-Resolution Network):
- HRNet在整个网络中保持了高分辨率的表示,同时通过多尺度融合策略有效地整合了低分辨率但富含语义的信息。
数据集和评价指标
常用的语义分割数据集包括PASCAL VOC、COCO、Cityscapes等。这些数据集提供了标注好的图像,用于训练和评估模型性能。
评价语义分割模型的标准通常包括:
- 像素准确率 (Pixel Accuracy):所有正确分类的像素占总像素的比例。
- 平均交并比 (Mean Intersection over Union, mIoU):这是最常用的评价指标之一,计算每个类别的IoU(交集除以并集),然后取平均值。
- 频率加权交并比 (Frequency Weighted IoU):考虑每个类别的出现频率,对mIoU进行加权。
总结
随着硬件性能的提升和算法的进步,深度学习语义分割已经取得了显著的进展。现代模型不仅能在速度上满足实时应用的需求,还能提供非常精确的分割结果。未来的研究可能会集中在提高模型效率、增强跨域泛化能力以及探索无监督或弱监督的学习方法等方面。
DeepLab
DeepLab 是一种专门为语义分割任务设计的深度学习模型,由 Google 团队提出。它在处理具有复杂结构和多尺度对象的图像时表现出色,能够精确地捕捉边界信息,并且有效地解决了传统卷积神经网络(CNN)中由于下采样操作导致的空间分辨率损失的问题。
DeepLab 的核心技术
-
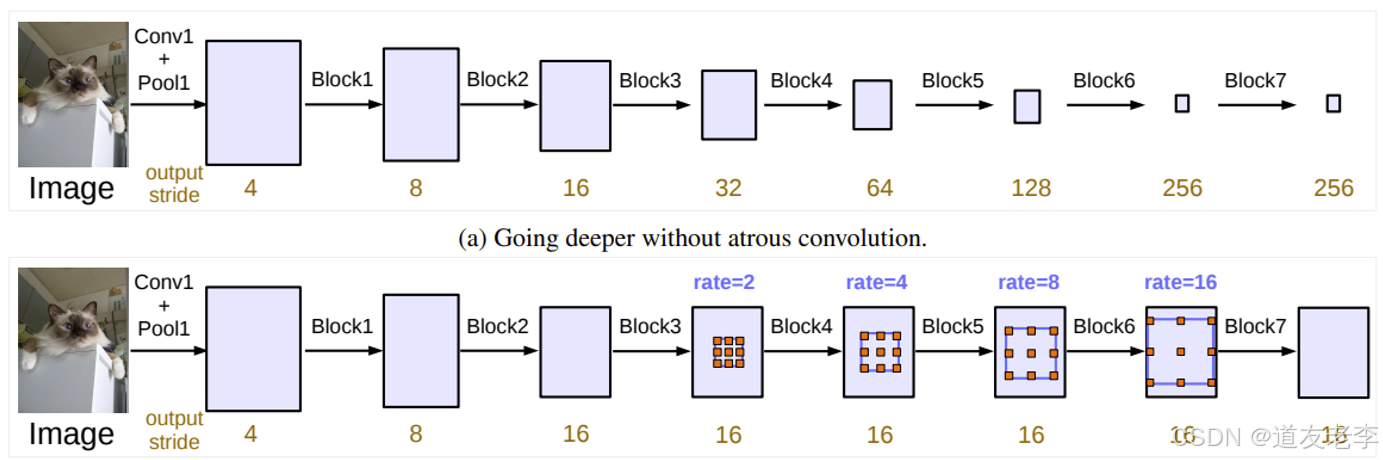
空洞卷积(Atrous Convolution / Dilated Convolution)
- 空洞卷积是在标准卷积的基础上增加了一个参数——膨胀率(dilation rate)。通过调整膨胀率,可以在不改变特征图尺寸的情况下扩大感受野,从而捕获更广泛的空间上下文信息。
- 这使得 DeepLab 能够在保持较高空间分辨率的同时,利用较大的感受野来获取丰富的上下文信息,这对语义分割非常有用。
-
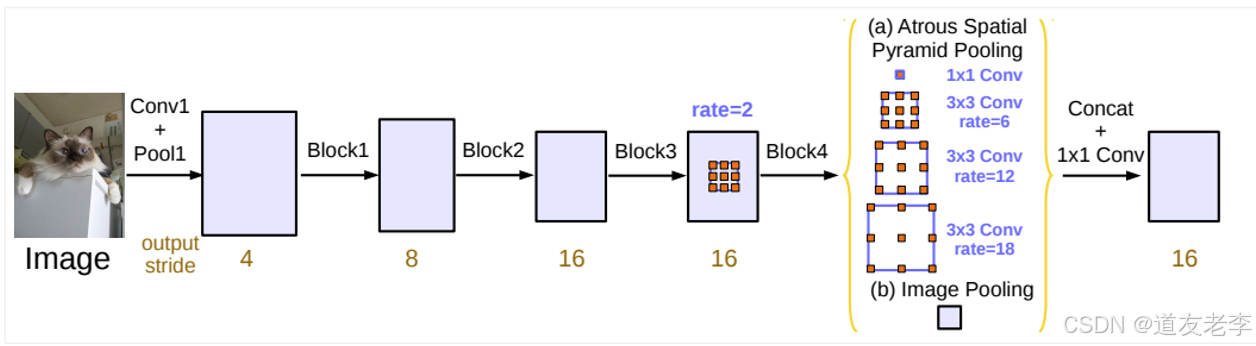
多尺度推理(Multi-scale Context Aggregation)
- DeepLab 采用多种方法来聚合不同尺度的信息。例如,在早期版本中使用了多尺度输入图像进行推理;而在后来的版本中,则引入了空洞空间金字塔池化(ASPP, Atrous Spatial Pyramid Pooling),即在同一层应用多个不同膨胀率的空洞卷积核,以覆盖不同的尺度。
- ASPP 可以看作是一种特殊的池化层,它通过组合来自不同尺度的感受野输出,增强了对多尺度物体的理解能力。
-
跳跃连接与解码器模块(Skip Connections and Decoder Module)
- 在某些 DeepLab 版本中,如 DeepLab v3+,加入了类似 U-Net 的跳跃连接机制,将低层次的细节信息传递给高层次的特征表示,帮助恢复精细的物体边界。
- 解码器模块则用于进一步提升分割结果的质量,特别是对于小目标或细长结构的检测更加有效。
-
批量归一化(Batch Normalization)
- 批量归一化有助于加速训练过程并提高模型泛化性能。DeepLab 模型通常会在每个卷积层之后添加 BN 层,以稳定和优化学习过程。
-
预训练权重迁移学习
- DeepLab 常常基于已有的大规模数据集(如 ImageNet)上预训练好的 CNN 模型(如 ResNet、Xception)作为骨干网络,然后针对特定的语义分割任务进行微调。这种迁移学习策略不仅提高了模型的初始表现,还减少了训练时间和计算资源需求。
DeepLab 的发展历史
- DeepLab v1:首次引入了空洞卷积的概念,用以解决卷积过程中因池化和下采样带来的分辨率降低问题。
- DeepLab v2:增加了 ASPP 结构,更好地处理了多尺度物体,并引入了条件随机场(CRF)后处理步骤来改善分割边缘质量。
- DeepLab v3:改进了 ASPP 设计,移除了 CRF 后处理,转而依赖更强大的网络架构来实现更好的分割效果。
- DeepLab v3+:引入了解码器模块,结合了编码器-解码器框架的优点,进一步提升了分割精度,特别是在细粒度结构上的表现。
总之,DeepLab 系列模型通过不断创新和技术改进,成为了语义分割领域的重要研究方向之一,并为后续的工作提供了宝贵的参考和启发。
DeepLab V3
引入了Multi-Grid,改进了 ASPP 设计,移除了 CRF 后处理,转而依赖更强大的网络架构来实现更好的分割效果
网络结构
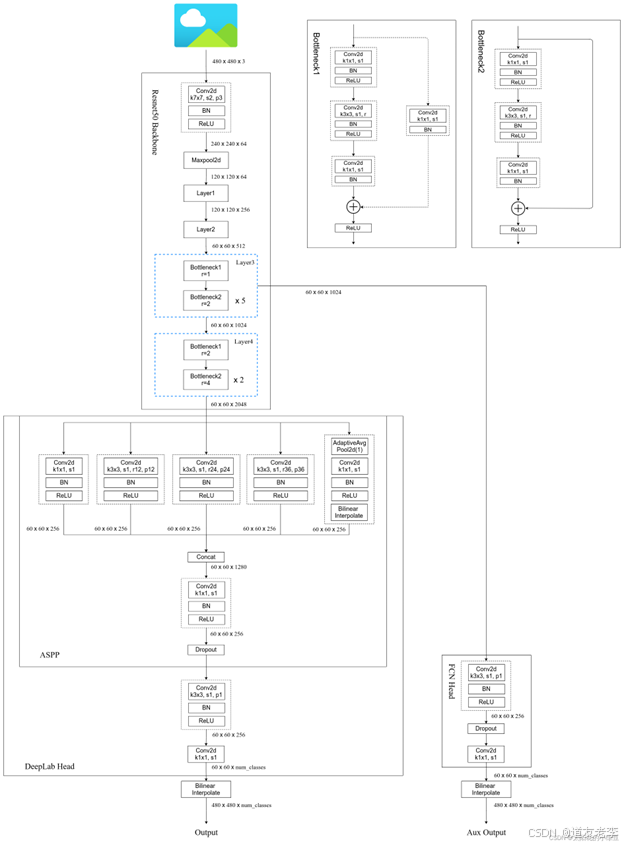
获取多尺度信息架构
Cascade Model
ASPP Model
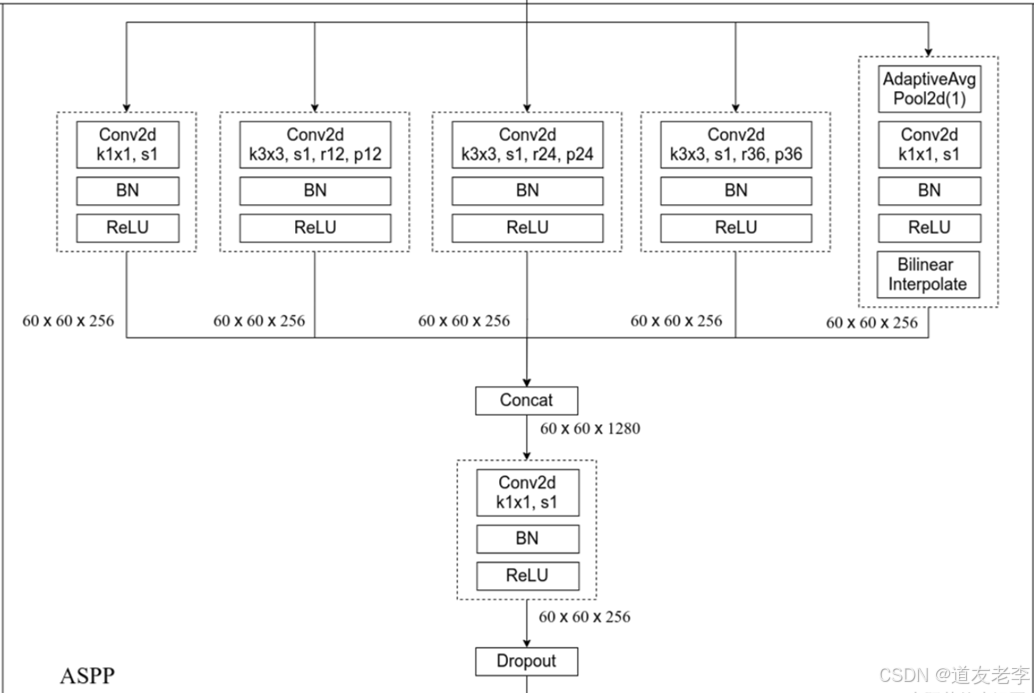
Multi-Grid
Pytorch官方实现的DeepLab V3

该项目主要是来自pytorch官方torchvision模块中的源码
- https://github.com/pytorch/vision/tree/main/torchvision/models/segmentation
环境配置
- Python3.6/3.7/3.8
- Pytorch1.10
- Ubuntu或Centos(Windows暂不支持多GPU训练)
- 最好使用GPU训练
- 详细环境配置见
requirements.txt
文件结构
├── src: 模型的backbone以及DeepLabv3的搭建
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取VOC数据集
├── train.py: 以deeplabv3_resnet50为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
├── validation.py: 利用训练好的权重验证/测试数据的mIoU等指标,并生成record_mAP.txt文件
└── pascal_voc_classes.json: pascal_voc标签文件
预训练权重下载地址
- 注意:官方提供的预训练权重是在COCO上预训练得到的,训练时只针对和PASCAL VOC相同的类别进行了训练,所以类别数是21(包括背景)
- deeplabv3_resnet50: https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth
- deeplabv3_resnet101: https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth
- deeplabv3_mobilenetv3_large_coco: https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth
- 注意,下载的预训练权重记得要重命名,比如在train.py中读取的是
deeplabv3_resnet50_coco.pth文件,
不是deeplabv3_resnet50_coco-cd0a2569.pth
数据集,本项目使用的是PASCAL VOC2012数据集
-
Pascal VOC2012 train/val数据集下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
如果想了解PASCAL VOC 数据集请参考目标检测课程.
训练方法
- 确保提前准备好数据集
- 确保提前下载好对应预训练模型权重
- 若要使用单GPU或者CPU训练,直接使用train.py训练脚本
- 若要使用多GPU训练,使用
torchrun --nproc_per_node=8 train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量 - 如果想指定使用哪些GPU设备可在指令前加上
CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备) CUDA_VISIBLE_DEVICES=0,3 torchrun --nproc_per_node=2 train_multi_GPU.py
注意事项
- 在使用训练脚本时,注意要将’–data-path’(VOC_root)设置为自己存放’VOCdevkit’文件夹所在的根目录
- 在使用预测脚本时,要将’weights_path’设置为你自己生成的权重路径。
- 使用validation文件时,注意确保你的验证集或者测试集中必须包含每个类别的目标,并且使用时只需要修改’–num-classes’、‘–aux’、‘–data-path’和’–weights’即可,其他代码尽量不要改动
实现代码
src文件目录
- deeplabv3_model.py
from collections import OrderedDict
from typing import Dict, List
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from .resnet_backbone import resnet50, resnet101
from .mobilenet_backbone import mobilenet_v3_large
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
# 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
class DeepLabV3(nn.Module):
"""
Implements DeepLabV3 model from
`"Rethinking Atrous Convolution for Semantic Image Segmentation"
`_.
Args:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
__constants__ = ['aux_classifier']
def __init__(self, backbone, classifier, aux_classifier=None):
super(DeepLabV3, self).__init__()
self.backbone = backbone
self.classifier = classifier
self.aux_classifier = aux_classifier
def forward(self, x: Tensor) -> Dict[str, Tensor]:
input_shape = x.shape[-2:]
# contract: features is a dict of tensors
features = self.backbone(x)
result = OrderedDict()
x = features["out"]
x = self.classifier(x)
# 使用双线性插值还原回原图尺度
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["out"] = x
if self.aux_classifier is not None:
x = features["aux"]
x = self.aux_classifier(x)
# 使用双线性插值还原回原图尺度
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["aux"] = x
return result
class FCNHead(nn.Sequential):
def __init__(self, in_channels, channels):
inter_channels = in_channels // 4
super(FCNHead, self).__init__(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(inter_channels),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(inter_channels, channels, 1)
)
class ASPPConv(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:
super(ASPPConv, self).__init__(
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
size = x.shape[-2:]
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:
super(ASPP, self).__init__()
modules = [
nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
]
rates = tuple(atrous_rates)
for rate in rates:
modules.append(ASPPConv(in_channels, out_channels, rate))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5)
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
_res = []
for conv in self.convs:
_res.append(conv(x))
res = torch.cat(_res, dim=1)
return self.project(res)
class DeepLabHead(nn.Sequential):
def __init__(self, in_channels: int, num_classes: int) -> None:
super(DeepLabHead, self).__init__(
ASPP(in_channels, [12, 24, 36]),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, num_classes, 1)
)
def deeplabv3_resnet50(aux, num_classes=21, pretrain_backbone=False):
# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'
# 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth'
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet50 backbone预训练权重
backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = DeepLabHead(out_inplanes, num_classes)
model = DeepLabV3(backbone, classifier, aux_classifier)
return model
def deeplabv3_resnet101(aux, num_classes=21, pretrain_backbone=False):
# 'resnet101_imagenet': 'https://download.pytorch.org/models/resnet101-63fe2227.pth'
# 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth'
backbone = resnet101(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet101 backbone预训练权重
backbone.load_state_dict(torch.load("resnet101.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = DeepLabHead(out_inplanes, num_classes)
model = DeepLabV3(backbone, classifier, aux_classifier)
return model
def deeplabv3_mobilenetv3_large(aux, num_classes=21, pretrain_backbone=False):
# 'mobilenetv3_large_imagenet': 'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'
# 'depv3_mobilenetv3_large_coco': "https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth"
backbone = mobilenet_v3_large(dilated=True)
if pretrain_backbone:
# 载入mobilenetv3 large backbone预训练权重
backbone.load_state_dict(torch.load("mobilenet_v3_large.pth", map_location='cpu'))
backbone = backbone.features
# Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.
# The first and last blocks are always included because they are the C0 (conv1) and Cn.
stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "is_strided", False)] + [len(backbone) - 1]
out_pos = stage_indices[-1] # use C5 which has output_stride = 16
out_inplanes = backbone[out_pos].out_channels
aux_pos = stage_indices[-4] # use C2 here which has output_stride = 8
aux_inplanes = backbone[aux_pos].out_channels
return_layers = {str(out_pos): "out"}
if aux:
return_layers[str(aux_pos)] = "aux"
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = DeepLabHead(out_inplanes, num_classes)
model = DeepLabV3(backbone, classifier, aux_classifier)
return model
- mobilenet_backbone.py
from typing import Callable, List, Optional
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None,
dilation: int = 1):
padding = (kernel_size - 1) // 2 * dilation
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
dilation=dilation,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
self.out_channels = out_planes
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
dilation: int,
width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS" # whether using h-swish activation
self.stride = stride
self.dilation = dilation
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers: List[nn.Module] = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
stride = 1 if cnf.dilation > 1 else cnf.stride
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=stride,
dilation=cnf.dilation,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
if cnf.use_se:
layers.append(SqueezeExcitation(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity))
self.block = nn.Sequential(*layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False,
dilated: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" .
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
dilated: whether using dilated conv
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
dilation = 2 if dilated else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilation
bneck_conf(16, 3, 16, 16, False, "RE", 1, 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2, 1), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1, 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2, 1), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2, 1), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1, 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1, 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2, dilation), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False,
dilated: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" .
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
dilated: whether using dilated conv
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
dilation = 2 if dilated else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilation
bneck_conf(16, 3, 16, 16, True, "RE", 2, 1), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2, 1), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1, 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2, 1), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1, 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1, 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2, dilation), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
- resnet_backbone.py
import torch
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(block, layers, **kwargs):
model = ResNet(block, layers, **kwargs)
return model
def resnet50(**kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 6, 3], **kwargs)
def resnet101(**kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 23, 3], **kwargs)
train_utils文件目录
- distributed_utils.py
from collections import defaultdict, deque
import datetime
import time
import torch
import torch.distributed as dist
import errno
import os
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{value:.4f} ({global_avg:.4f})"
self.deque = deque(maxlen=window_size)
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self):
d = torch.tensor(list(self.deque))
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
class ConfusionMatrix(object):
def __init__(self, num_classes):
self.num_classes = num_classes
self.mat = None
def update(self, a, b):
n = self.num_classes
if self.mat is None:
# 创建混淆矩阵
self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)
with torch.no_grad():
# 寻找GT中为目标的像素索引
k = (a >= 0) & (a < n)
# 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)
inds = n * a[k].to(torch.int64) + b[k]
self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)
def reset(self):
if self.mat is not None:
self.mat.zero_()
def compute(self):
h = self.mat.float()
# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
acc_global = torch.diag(h).sum() / h.sum()
# 计算每个类别的准确率
acc = torch.diag(h) / h.sum(1)
# 计算每个类别预测与真实目标的iou
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
return acc_global, acc, iu
def reduce_from_all_processes(self):
if not torch.distributed.is_available():
return
if not torch.distributed.is_initialized():
return
torch.distributed.barrier()
torch.distributed.all_reduce(self.mat)
def __str__(self):
acc_global, acc, iu = self.compute()
return (
'global correct: {:.1f}
'
'average row correct: {}
'
'IoU: {}
'
'mean IoU: {:.1f}').format(
acc_global.item() * 100,
['{:.1f}'.format(i) for i in (acc * 100).tolist()],
['{:.1f}'.format(i) for i in (iu * 100).tolist()],
iu.mean().item() * 100)
class MetricLogger(object):
def __init__(self, delimiter=" "):
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None):
i = 0
if not header:
header = ''
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
if torch.cuda.is_available():
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'
])
else:
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'
])
MB = 1024.0 * 1024.0
for obj in iterable:
data_time.update(time.time() - end)
yield obj
iter_time.update(time.time() - end)
if i % print_freq == 0:
eta_seconds = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
if torch.cuda.is_available():
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('{} Total time: {}'.format(header, total_time_str))
def mkdir(path):
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()
def is_main_process():
return get_rank() == 0
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
elif hasattr(args, "rank"):
pass
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
setup_for_distributed(args.rank == 0)
- train_and_eval.py
import torch
from torch import nn
import train_utils.distributed_utils as utils
def criterion(inputs, target):
losses = {}
for name, x in inputs.items():
# 忽略target中值为255的像素,255的像素是目标边缘或者padding填充
losses[name] = nn.functional.cross_entropy(x, target, ignore_index=255)
if len(losses) == 1:
return losses['out']
return losses['out'] + 0.5 * losses['aux']
def evaluate(model, data_loader, device, num_classes):
model.eval()
confmat = utils.ConfusionMatrix(num_classes)
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, 100, header):
image, target = image.to(device), target.to(device)
output = model(image)
output = output['out']
confmat.update(target.flatten(), output.argmax(1).flatten())
confmat.reduce_from_all_processes()
return confmat
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
return metric_logger.meters["loss"].global_avg, lr
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
# warmup后lr倍率因子从1 -> 0
# 参考deeplab_v2: Learning rate policy
return (1 - (x - warmup_epochs * num_step) / ((epochs - warmup_epochs) * num_step)) ** 0.9
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
根目录
- train.py
import os
import time
import datetime
import torch
from src import deeplabv3_resnet50
from train_utils import train_one_epoch, evaluate, create_lr_scheduler
from my_dataset import VOCSegmentation
import transforms as T
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
min_size = int(0.5 * base_size)
max_size = int(2.0 * base_size)
trans = [T.RandomResize(min_size, max_size)]
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
trans.extend([
T.RandomCrop(crop_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
self.transforms = T.Compose(trans)
def __call__(self, img, target):
return self.transforms(img, target)
class SegmentationPresetEval:
def __init__(self, base_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.RandomResize(base_size, base_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def get_transform(train):
base_size = 520
crop_size = 480
return SegmentationPresetTrain(base_size, crop_size) if train else SegmentationPresetEval(base_size)
def create_model(aux, num_classes, pretrain=True):
model = deeplabv3_resnet50(aux=aux, num_classes=num_classes)
if pretrain:
weights_dict = torch.load("./src/deeplabv3_resnet50.pth", map_location='cpu')
if num_classes != 21:
# 官方提供的预训练权重是21类(包括背景)
# 如果训练自己的数据集,将和类别相关的权重删除,防止权重shape不一致报错
for k in list(weights_dict.keys()):
if "classifier.4" in k:
del weights_dict[k]
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
return model
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
batch_size = args.batch_size
# segmentation nun_classes + background
num_classes = args.num_classes + 1
# 用来保存训练以及验证过程中信息
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> train.txt
train_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=True),
txt_name="train.txt")
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> val.txt
val_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=False),
txt_name="val.txt")
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=1,
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = create_model(aux=args.aux, num_classes=num_classes)
model.to(device)
params_to_optimize = [
{"params": [p for p in model.backbone.parameters() if p.requires_grad]},
{"params": [p for p in model.classifier.parameters() if p.requires_grad]}
]
if args.aux:
params = [p for p in model.aux_classifier.parameters() if p.requires_grad]
params_to_optimize.append({"params": params, "lr": args.lr * 10})
optimizer = torch.optim.SGD(
params_to_optimize,
lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
# import matplotlib.pyplot as plt
# lr_list = []
# for _ in range(args.epochs):
# for _ in range(len(train_loader)):
# lr_scheduler.step()
# lr = optimizer.param_groups[0]["lr"]
# lr_list.append(lr)
# plt.plot(range(len(lr_list)), lr_list)
# plt.show()
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
confmat = evaluate(model, val_loader, device=device, num_classes=num_classes)
val_info = str(confmat)
print(val_info)
# write into txt
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
train_info = f"[epoch: {epoch}]
"
f"train_loss: {mean_loss:.4f}
"
f"lr: {lr:.6f}
"
f.write(train_info + val_info + "
")
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
if args.amp:
save_file["scaler"] = scaler.state_dict()
torch.save(save_file, "save_weights/model_{}.pth".format(epoch))
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch deeplabv3 training")
parser.add_argument("--data-path", default="/data/", help="VOCdevkit root")
parser.add_argument("--num-classes", default=20, type=int)
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=4, type=int)
parser.add_argument("--epochs", default=30, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
- predict.py
import os
import time
import json
import torch
from torchvision import transforms
import numpy as np
from PIL import Image
from src import deeplabv3_resnet50
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
def main():
aux = False # inference time not need aux_classifier
classes = 20
weights_path = "./save_weights/model_0.pth"
img_path = "./test.jpg"
palette_path = "./palette.json"
assert os.path.exists(weights_path), f"weights {weights_path} not found."
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(palette_path), f"palette {palette_path} not found."
with open(palette_path, "rb") as f:
pallette_dict = json.load(f)
pallette = []
for v in pallette_dict.values():
pallette += v
# get devices
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# create model
model = deeplabv3_resnet50(aux=aux, num_classes=classes+1)
# delete weights about aux_classifier
weights_dict = torch.load(weights_path, map_location='cpu')['model']
for k in list(weights_dict.keys()):
if "aux" in k:
del weights_dict[k]
# load weights
model.load_state_dict(weights_dict)
model.to(device)
# load image
original_img = Image.open(img_path)
# from pil image to tensor and normalize
data_transform = transforms.Compose([transforms.Resize(520),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init model
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
output = model(img.to(device))
t_end = time_synchronized()
print("inference+NMS time: {}".format(t_end - t_start))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
mask = Image.fromarray(prediction)
mask.putpalette(pallette)
mask.save("test_result.png")
if __name__ == '__main__':
main()