【Linux笔记】基础IO(下)
🔥个人主页🔥:孤寂大仙V
🌈收录专栏🌈:Linux
🌹往期回顾🌹:【Linux笔记】基础IO(上)
🔖流水不争,争的是滔滔不
- 一、Linux下一切皆文件
- 二、缓冲区
- 缓冲区简介
- 设置缓冲区的原因
- 缓冲类型/刷新条件满足
- 语言层面缓冲区的管理
- 简单设计libc库
一、Linux下一切皆文件
在 Linux 系统中,几乎所有的东西都被视为文件,包括硬件设备、网络连接、进程、用户等。这意味着系统将各种不同类型的资源都抽象成了文。件的形式,以便于进行统一的管理和操作。用户和应用程序可以使用相同的文件操作接口(如打开、读取、写入、关闭等)来访问和控制这些资源,而不必关心它们的具体物理形式或实现细节。
具体体现
- 硬件设备:每个硬件设备在 Linux 系统中都对应着一个或多个特殊文件,称为设备文件。例如,硬盘分区通常被表示为/dev/sda、/dev/sdb等文件,串口设备可能是/dev/ttyS0等。通过对这些设备文件进行读写操作,就可以实现对硬件设备的控制和数据传输。比如,向/dev/sda设备文件写入数据,实际上就是向对应的硬盘分区写入数据。
- 进程:在 Linux 中,进程也可以通过文件系统来访问和管理。/proc文件系统就是专门用于反映系统中进程的运行状态等信息的虚拟文件系统。每个进程在/proc目录下都有一个以其进程号命名的子目录,例如/proc/1234,其中包含了该进程的各种信息,如进程状态、内存使用情况、打开的文件列表等。可以通过读取这些文件来获取进程的相关信息,也可以通过写入特定文件来对进程进行一些控制操作。
- 网络连接:网络连接在 Linux 中也被视为文件。网络套接字(socket)可以像文件一样进行打开、读写和关闭操作。通过对网络套接字文件的操作,应用程序可以实现网络数据的发送和接收,从而实现网络通信功能。例如,使用send()和recv()函数对网络套接字文件进行读写,就可以发送和接收网络数据。
- 用户和组:用户和组的信息在 Linux 系统中通常存储在/etc/passwd和/etc/group等文件中。这些文件以特定的格式记录了用户和组的相关信息,如用户名、用户 ID、组名、组 ID 等。系统通过读取这些文件来进行用户身份验证、权限管理等操作。
优点
- 简化系统操作和管理:用户和应用程序只需要掌握一套统一的文件操作接口,就可以对各种不同类型的资源进行操作,降低了系统使用和管理的复杂性。
- 提高系统的可扩展性和兼容性:由于一切皆文件,新的硬件设备或系统资源可以很容易地通过添加相应的设备文件或虚拟文件系统来集成到系统中,而不需要对整个系统架构进行大规模的修改。
- 增强系统的安全性:通过对文件的权限管理,可以很方便地对各种资源的访问进行控制。不同的用户和用户组可以被赋予不同的文件访问权限,从而确保系统资源的安全使用。
“Linux 中的一切皆文件” 这一理念是 Linux 系统设计的核心思想之一,它为 Linux 系统带来了高度的灵活性、可扩展性和易用性,是 Linux 系统能够广泛应用于各种领域的重要原因之一。
下面通过一个操作系统的实例来理解
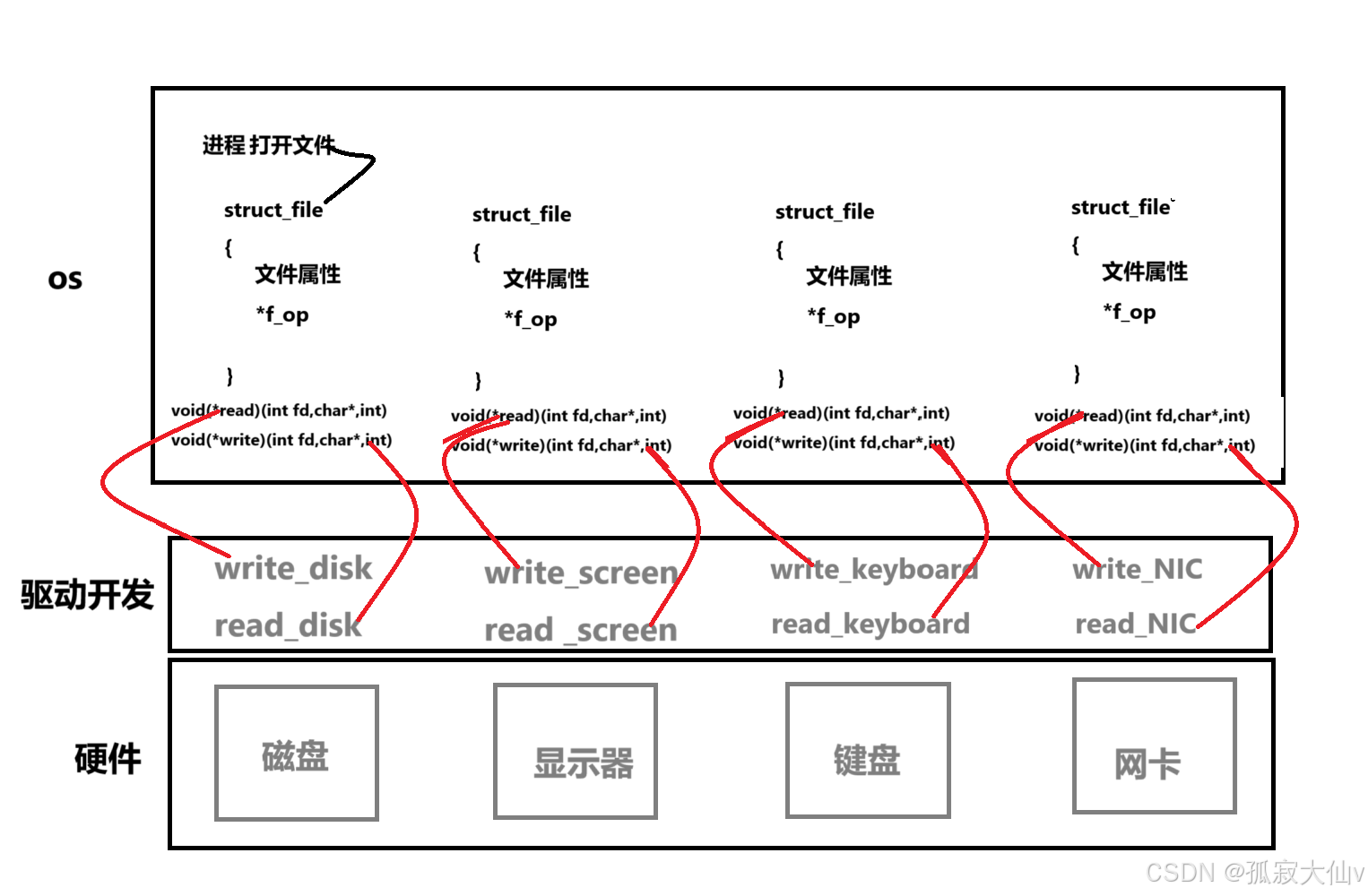
Linux中打开文件,操作系统都会为文件创建一个file结构体,file结构体内包含了许多指针封装了文件的许多属性和状态。里面有一个f_op。
f_op:指向 struct file_operations 结构体的指针,该结构体包含了一系列的函数指针,用于实现对该文件的各种操作,如
read、write、open、release 等。不同的文件系统或设备驱动可以实现自己的 file_operations结构体,以提供特定的操作行为。
file_operation 就是把系统调用和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都对应着⼀个系统调用。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从而完成了Linux设备驱动程序的工作。每一个外设都有自己的读和写,但是不同的外设的操作与函数实现不同,但通过struct_file中的file_operations中的函数让用户只通过file便可以完成Linux系统中的绝大部分操作。
二、缓冲区
缓冲区简介
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
设置缓冲区的原因
在进行文件读写操作时,如果不针对文件操作开辟专门的缓冲区,而是直接借助系统调用对磁盘执行读、写等操作,那么每一次文件读写,都需执行一次系统调用。而执行系统调用会引发 CPU 状态的切换,即从用户空间转换至内核空间,完成进程上下文的切换过程,这一过程会消耗一定的 CPU 时间。频繁地访问磁盘,会极大地影响程序的执行效率。
为了降低系统调用的使用频次,提升效率,我们可采用缓冲机制。例如,从磁盘读取信息时,在对磁盘文件操作过程中,一次性从文件读取大量数据存入缓冲区。后续对这部分数据的访问,便无需再次执行系统调用,直至缓冲区的数据读取完毕,再从磁盘读取新的数据。如此一来,能够显著减少磁盘的读写次数。加之计算机对缓冲区的操作速度远快于对磁盘的操作速度,使用缓冲区可大幅提升计算机的运行速度。
再比如,利用打印机打印文档时,鉴于打印机的打印速度相对较慢,我们先将文档输出至打印机对应的缓冲区,随后打印机自行逐步打印,在此期间,CPU 可用于处理其他事务。由此可见,缓冲区是位于输入输出设备与 CPU 之间的一块内存区域,用于缓存数据。它能使低速的输入输出设备与高速的 CPU 协调运作,避免低速输入输出设备占用 CPU 资源,释放 CPU 以实现高效工作。
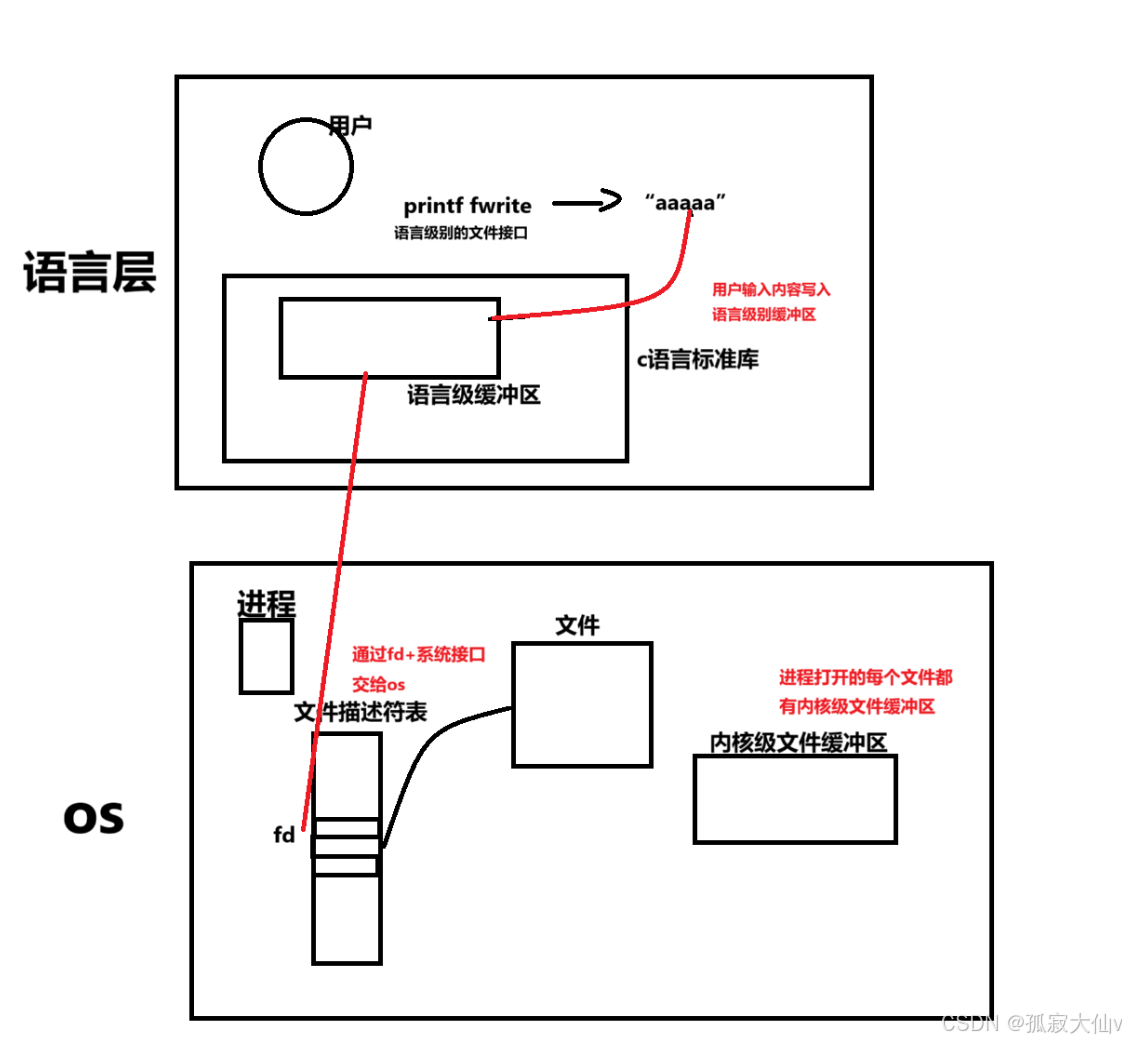
只要把数据交给OS就相当于交给了硬件。计算机数据流动的本质:一切皆文件。
缓冲类型/刷新条件满足
在 Linux 系统中,标准 I/O 库的缓冲区主要有全缓冲区、行缓冲区和无缓冲区三种类型,它们各自有着不同的工作方式和应用场景:
- 全缓冲区:采用全缓冲方式时,必须要将整个缓冲区填满,才会触发 I/O 系统调用操作。这种缓冲方式常用于磁盘文件操作。例如,当进程向磁盘文件写入数据时,数据先被存储在全缓冲区中,直到缓冲区被填满,内核才会将缓冲区中的数据写入磁盘;从磁盘文件读取数据时,也是一次性读取大量数据填满缓冲区,后续的读取操作先从缓冲区获取数据,直至缓冲区数据耗尽。
- 行缓冲区:在行缓冲模式下,标准 I/O 库函数在输入和输出过程中遇到换行符时,会执行系统调用操作。当操作的流与终端相关,如标准输入(stdin)和标准输出(stdout)时,通常采用行缓冲方式。标准 I/O 库为每一行设置了固定长度的缓冲区,一旦缓冲区被填满,即便尚未遇到换行符,也会执行 I/O 系统调用操作。一般情况下,行缓冲区的默认大小为 1024 字节。比如,使用printf函数输出字符串时,若字符串中包含换行符,或者输出的字符数量达到行缓冲区大小,数据就会被输出到终端。
- 无缓冲区:无缓冲区意味着标准 I/O 库不会对字符进行缓存,而是直接调用系统调⽤。标准出错流stderr通常采用无缓冲方式,这样可以确保出错信息能够迅速显示出来。例如,当程序出现错误并通过fprintf(stderr, “Error message ”)输出错误信息时,这些信息会立即被发送到终端显示,而不会在缓冲区中等待。
引发缓冲区刷新的特殊情况:
- 刷新区满了的时候
- flush语句进行刷新
关闭文件描述符1,也就是让本该写入显示器,现在写入文件。相当于重定向。
#include 但是没有内容,说明语言层面的缓冲区并没有写满所有不刷新。

这时我们用flush,强制刷新就刷新出来了。
#include 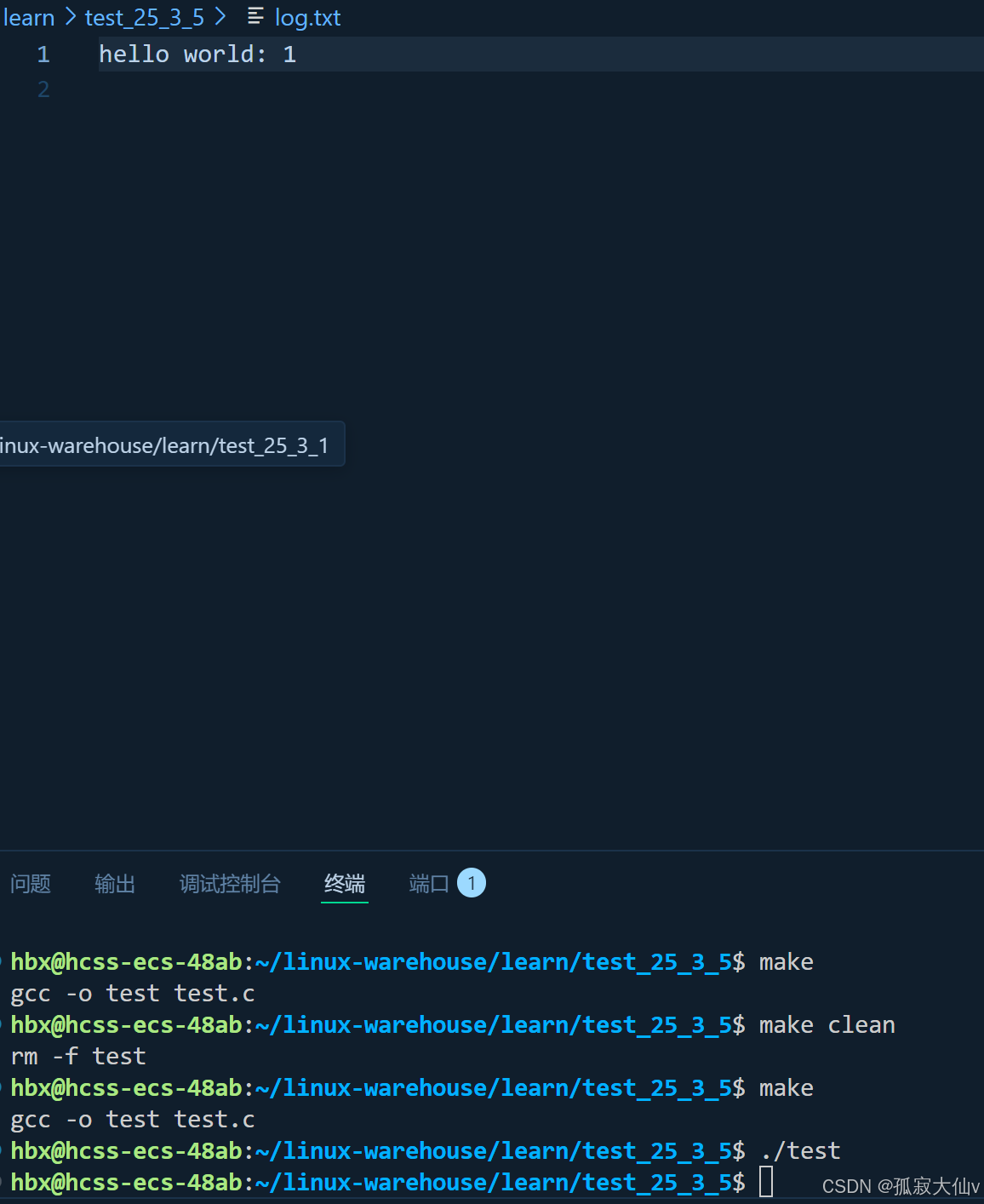
语言层面缓冲区的管理
FILE结构体是 C 标准库中用于处理文件操作的一个重要数据结构,它包含了许多与文件操作相关的信息和状态,其中就包括对缓冲区的管理信息。当使用标准 I/O 函数(如fopen、fread、fwrite等)进行文件操作时,FILE结构体负责记录缓冲区的状态、位置、大小等信息,以实现对文件数据的缓冲处理,从而提高 I/O 操作的效率。具体来说:
- 缓冲区的分配:在打开一个文件时,fopen函数会根据文件的类型和打开模式等因素,为FILE结构体关联的文件操作分配相应的缓冲区。例如,对于以读模式打开的普通文件,可能会分配一个全缓冲区;对于与终端相关的标准输入输出流,可能会分配行缓冲区。
- 数据的读写:当进行fread或fwrite等操作时,数据实际上是先在缓冲区中进行处理的。以fread为例,它会先尝试从缓冲区中读取数据,如果缓冲区中没有足够的数据,才会触发实际的系统调用从磁盘等设备读取数据到缓冲区,然后再从缓冲区中返回数据给用户程序。fwrite则是将数据先写入缓冲区,当缓冲区满或者执行fflush等操作时,才会将缓冲区中的数据写入到实际的文件或设备中。
- 缓冲区的刷新:FILE结构体中有一些机制来管理缓冲区的刷新时机。比如,当调用fflush函数时,会强制将缓冲区中的数据写入到文件或设备中,以确保数据的及时更新。另外,当FILE结构体被关闭时(通过fclose函数),也会自动刷新缓冲区,确保所有未写入的数据都被写入到文件中,避免数据丢失。
不过,C 语言中除了标准 I/O 库的FILE结构体管理的缓冲区外,还有其他类型的缓冲区,比如用户自己定义和管理的缓冲区,用于特定的目的和场景。这些缓冲区的管理与FILE结构体无关,完全由用户根据自己的需求进行分配、使用和释放。
#include 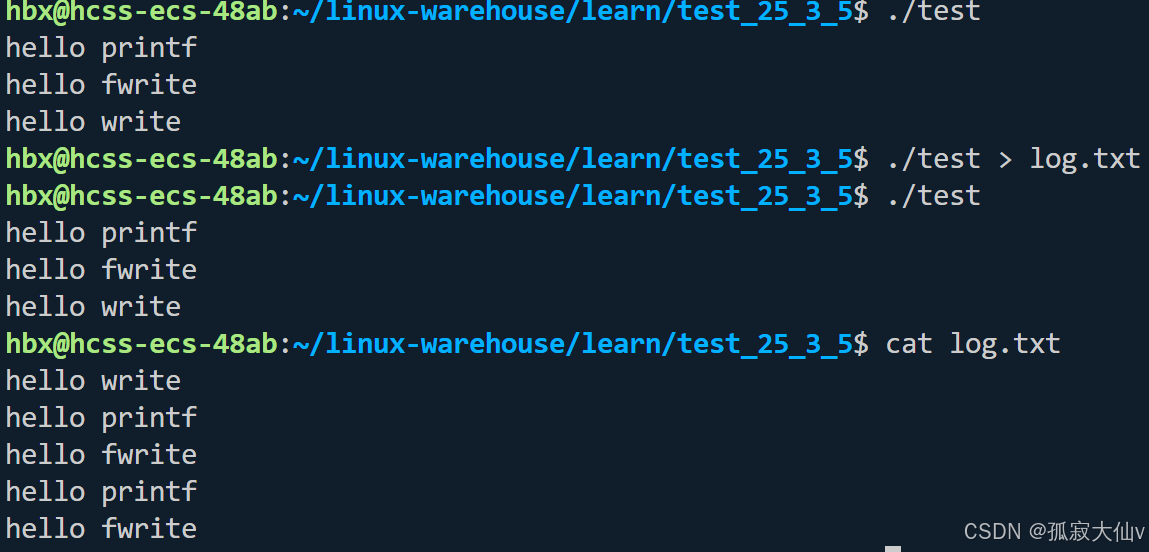
我们发现,printf和fwrite这两个库函数都输出了 2 次,而write(系统调用)只输出了 1 次。这一现象的产生,肯定与fork操作有关。以下是具体的分析:
- 缓冲方式的特性:一般来说,C 库函数在写入文件时采用的是全缓冲方式,而在写入显示器时采用的是行缓冲方式。
- 库函数的缓冲区:printf和fwrite库函数都自带缓冲区。当发生重定向到普通文件的情况时,数据的缓冲方式会从行缓冲转变为全缓冲。
- 缓冲区数据的刷新:由于我们放在缓冲区中的数据,不会被立即刷新,甚至在fork操作之后依然如此。只有在进程退出之后,缓冲区的数据才会被统一刷新并写入文件当中。
- fork 时的数据情况:在执行fork操作时,父子进程的数据会发生写时拷贝。所以当父进程准备刷新缓冲区时,子进程也会拥有同样的一份数据,这样就会随即产生两份数据输出的现象。
- write 系统调用的情况:write系统调用没有出现上述变化,这说明write没有所谓的用户级缓冲区。
综上,printf和fwrite库函数自带缓冲区,而write系统调用没有带缓冲区。这里我们所说的缓冲区,都是用户级缓冲区。实际上,为了提升整机性能,操作系统也会提供相关的内核级缓冲区,不过这不在我们的讨论范围之内。
关于这个缓冲区的提供者,printf、fwrite是库函数,write是系统调用,库函数处于系统调用的 “上层”,是对系统调用的 “封装”。write没有缓冲区,而printf、fwrite有,这足以说明该缓冲区是额外添加的。又因为这是在 C 语言环境中,所以这个缓冲区是由 C 标准库提供的。
简单设计libc库
my_stdio.h
#pragma once
#includemy_stdio.c
#include "my_stdio.h"
#include