【Linux】文件的内核级缓冲区、重定向、用户级缓冲区(详解)
一.文件内核级缓冲区
在一个struct file内部还要有一个数据结构-----文件的内核级缓冲区
打开文件,为我们创建struct file,与该文件的所对应的操作表函数指针集合,还要提供一个文件的内核级缓冲区
1.write写入具体操作
当我们去对一个文件写入的时候,那么是如何进行写入的呢?
比如上层调用write(3,"hello word",..),根据PCB找到file_struct,然后找到fd_array[],然后拿到文件描述符表,找到目标3号 文件,然后把字符串“hello word”,拷贝到文件内核级缓冲区,write给我们进行拷贝,file会找到ops函数指针集合中write方法,然后通过这个方法,把我们文件内核及缓冲区的内容刷新到我们对应的外设中,当然由文件内核级缓冲区刷新到外设的过程什么时候刷新是由OS自主决定的,
所有write本质是一个拷贝函数,从用户拷贝到内核,文件这些数据结构都是OS给我们提供的。
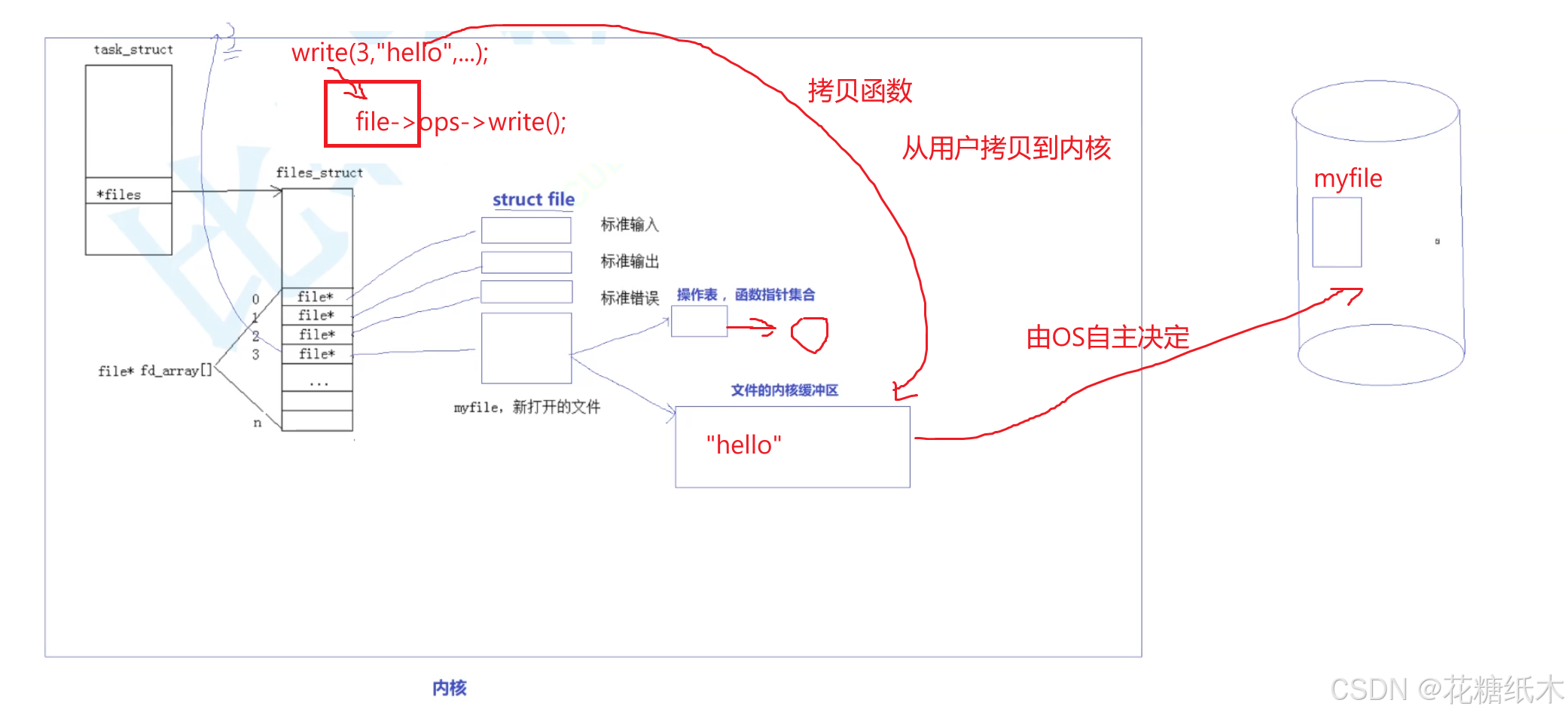
这就是我们平时写文件的时候,比如word文档的时候,已经键盘里进行输入了,为什么最后还要进行保存,保存是在干什么?写只是把数据写到文件的内核级缓冲区,保存是把内容从缓冲区刷新到外设,这个过程叫做写入!!!
补充:每个文件都有属于自己的文件操作表,都有属于自己的内核级缓冲区。
2.read读取具体操作
当我们去对一个文件写入的时候,那么是如何进行写入的呢?
上层调用read(3,buffer,...),在读的时候本质是在做什么呢?
找到进程,找到文件描述符表,找到文件,然后他会检测当前数据是在文件内核级缓冲区内,还是在磁盘上,如果在读的时候,数据没在缓冲区里面,就会触发我们read方法,把数据从磁盘读到缓冲区里,然后read开始进行把缓冲区里的数据拷贝到buffer中。
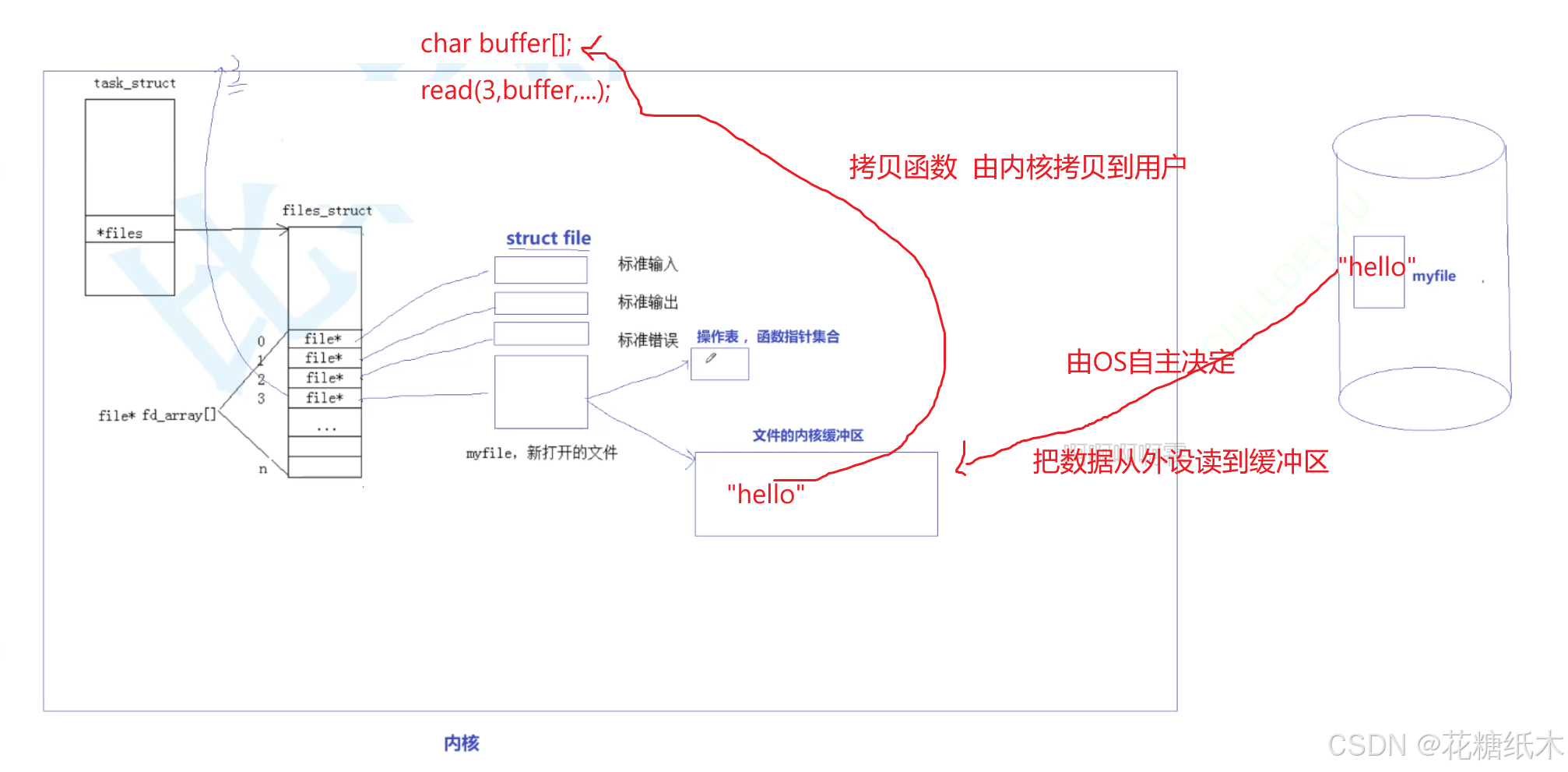
读到缓冲区之后,才能完成拷贝,这个过程,很明显就会阻塞住,这就是我们平常调read会阻塞的原因,
最典型scanf,调用scanf时,scanf对应的外设中根本没有数据,此时调用scanf就会阻塞,当你一输入的时候,这个数据里面就被读到缓冲区里,然后上层通过read就把数据从内核拷贝到用户,本质上也是拷贝函数!!!
3.修改的具体操作
如果要进行修改文件内容的一部分,要修改的话我们进程是没办法直接对磁盘里的文件进行修改,所以要修改,第一步,把文件的相关数据加载到内核级缓冲区内,然后读到用户空间,修改完后,再写回内核级缓冲区,再刷新到外设,修改的本质也是先读取,再写入,
读取由修改都是要把数据从外设读到缓冲区内进行操作,
换言之,我们对应的文件struct file里包含文件属性,操作表,每个文件的内核级缓冲区。
所以把我们外部设备,当我们打开这个文件,如果文件里本来就有内容,OS可以自主决定什么时候把数据从内核级缓冲区刷新到外设,那可不可以自主决定提前把文件数据一部分进行预加载呢?
也就是说,还没访问到这个数据的时候,提前给预加载了,这个是可以的。
4.为什么要存在这个缓冲区呢?
因为内存的的操作非常块,外设的操作非常慢,
如果每一次写入一部分数据,都要进行一次IO访问外设,如果写一百次就要一百次IO,这样耗费的时间就特别长,而我们数据从内存拷贝到内存这个速度是特别快的,我们把一百次的数据积累到一块,统一坐刷新,这样就可以节省99次IO的时间,
所以缓冲区的存在,提高了效率!!!!
这时刷新,要是读取呢?
在OS有空闲时间的时候,在进行数据读取的时候,OS也可以自主决定把文件内一部分数据提前预加载到缓冲区里,上层在进行读取的时候,就能直接进行读取,这样就把IO的时间成本嫁接在OS空闲的时候,当OS忙的时候就可以直接从缓冲区里进行读,就不用再进行加载,这样也提高了效率。
总结:缓冲区存在的意义就是变相的提高IO的效率!!!!
我们来看看内核源代码,来看看内核级缓冲区的存在:
二.重定向
1.认识
先说一个结论:进程打开一个文件,需要给文件分配新的的文件描述符fd,fd的分配规则是,最小的没有被使用的fd!!!
我们看看正常打开几个文件,他们fd是多少:
#include
#include
#include
#include
#include
int main()
{
int fd1 = open("log.txt1",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd2 = open("log.txt2",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd3 = open("log.txt3",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd4 = open("log.txt4",O_WRONLY | O_CREAT | O_APPEND,0666);
printf("fd1: %d
",fd1);
printf("fd2: %d
",fd2);
printf("fd3: %d
",fd3);
printf("fd4: %d
",fd4);
close(fd1);
close(fd3);
close(fd3);
close(fd4);
return 0;
} 
正常打开文件,是从3开始依次向后,这时为什么呢?在上一篇文件说到,因为进程启动,会默认打开三个输入输出流,参考:【linux】文件描述符fd。
当我们试着把0和2号文件进行关闭,再来看看结果:
#include#include #include #include #include int main() { close(0); close(2); int fd1 = open("log.txt1",O_WRONLY | O_CREAT | O_APPEND,0666); int fd2 = open("log.txt2",O_WRONLY | O_CREAT | O_APPEND,0666); int fd3 = open("log.txt3",O_WRONLY | O_CREAT | O_APPEND,0666); int fd4 = open("log.txt4",O_WRONLY | O_CREAT | O_APPEND,0666); printf("fd1: %d ",fd1); printf("fd2: %d ",fd2); printf("fd3: %d ",fd3); printf("fd4: %d ",fd4); close(fd1); close(fd3); close(fd3); close(fd4); return 0; }
这时发现文件打开就变成0 2 3 4,根据fd分配规则,最小的没有被使用,因为提前关闭了0和2,所以最小的没被使用的 fd就是0和2,从0和2开始进行分配。

那么如果把一号文件描述符关掉,结果如下:
#include
#include
#include
#include
int main()
{
close(1);
int fd1 = open("log.txt1",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd2 = open("log.txt2",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd3 = open("log.txt3",O_WRONLY | O_CREAT | O_APPEND,0666);
int fd4 = open("log.txt4",O_WRONLY | O_CREAT | O_APPEND,0666);
printf("fd1: %d
",fd1);
printf("fd2: %d
",fd2);
printf("fd3: %d
",fd3);
printf("fd4: %d
",fd4);
close(fd1);
close(fd3);
close(fd3);
close(fd4);
return 0;
} 
把一号文件描述符关掉,后来打开log.txt1文件,然后进行prin