Ubuntu20.04安装Nvidia显卡驱动教程以及深度学习环境搭建
前言
记录一下新系统环境安装的过程,如果前面没有删除干净的,可以查看最下面参考文章中的链接。
Nvidia显卡驱动教程
先查询电脑最适合的显卡驱动版本
ubuntu-drivers devices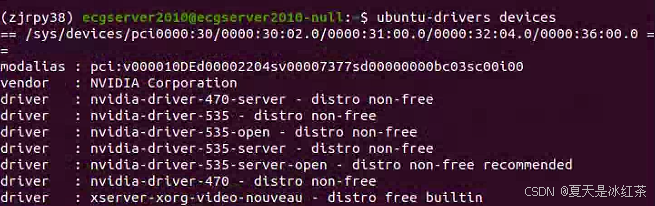
最佳显卡驱动版本为nvidia-driver-535-server-open,但我自己下载后重启发现没有找到设备,安装下面的问题就解决了。
sudo apt install nvidia-driver-535如果你不需要服务器优化版本,可以选择nvidia-driver-535。这是标准版本的驱动,适合大多数桌面和工作站环境。
安装后重启
sudo reboot然后输入验证即可
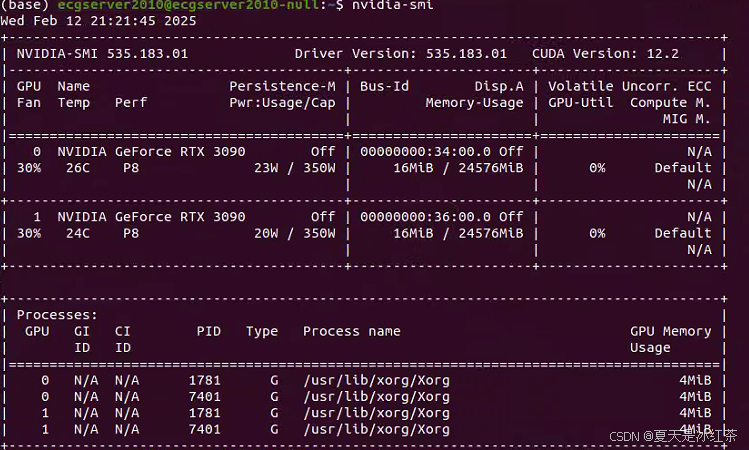
nvidia-smi我这里的设备装有两块NVIDIA GeForce RTX 3090显卡,CUDA版本为12.2。
安装miniconda
进入这里清华大学开源软件镜像站 | Tsinghua Open Source Mirror,搜索anaconda,进入后选择miniconda。
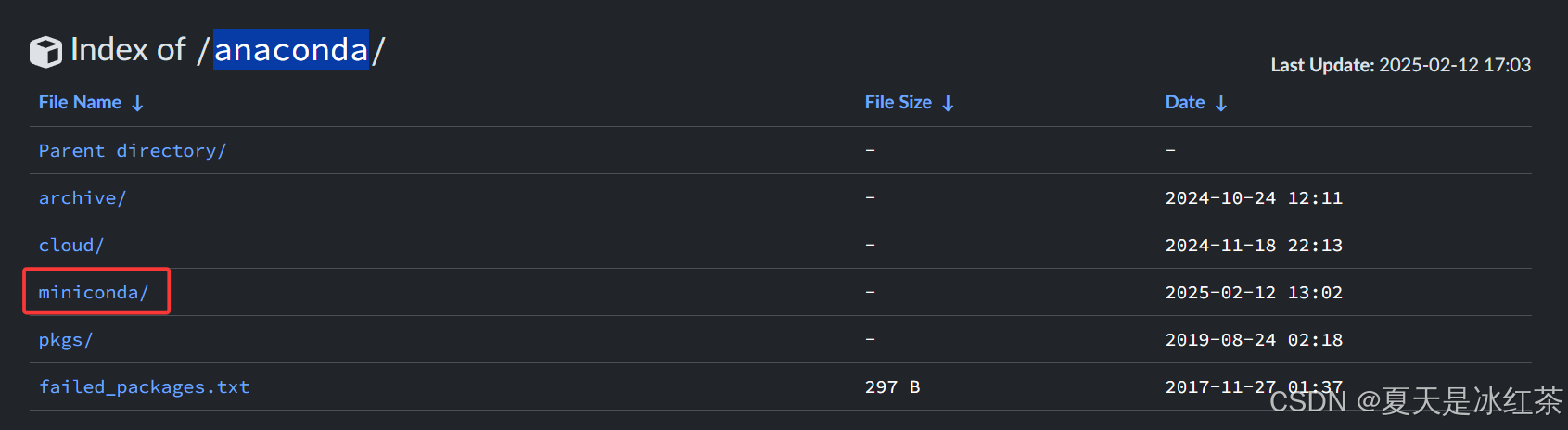
找到适合你的Linux系统版本的Miniconda安装程序,右键复制链接地址。
打开终端,利用wget命令下载安装程序文件:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py38_4.9.2-Linux-x86_64.sh接着,运行即可
bash Miniconda3-py38_4.9.2-Linux-x86_64.sh在安装脚本时候遇到权限问题,可尝试使用下面的指令
chmod +x Miniconda3-py38_4.9.2-Linux-x86_64.sh如果出现conda:未找到命令
source ~/.bashrc创建虚拟环境
查看当前的虚拟环境
conda env list创建新环境
conda create -n zjrpy38 python=3.8激活环境
conda activate zjrpy38退出环境:deactivate,我通常会省去这步,直接activate 其他的虚拟环境名,这样方便转换到其他虚拟环境。
删除虚拟环境:
conda remove -n zjrpy38 –all下载第三方库
torch请从此处查看Previous PyTorch Versions | PyTorch:
请注意,这里的cuda版本应该比你当前的设备要小,最好不要用相同版本的。
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121一些可能会用到的
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scikit-image -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
安装Pycharm
pycharm的安装包下载网址:https://www.jetbrains.com/zh-cn/pycharm/download/#section=linux
解压之后
你可以进入下面的bin文件夹
cd /home/ecgserver2010/AI/pycharm/pycharm-community-2024.3.2/bin然后输入
sh pycharm.sh每次这样不太方便,这里我们来建立桌面快捷方式,先进入下面的目录,这是存储应用程序快捷方式的目录。
cd /usr/share/applications/使用文本编辑器创建一个新的 .desktop 文件
sudo nano pycharm.desktop
在编辑器中添加以下内容:
[Desktop Entry]
Name=PyCharm
Comment=Python IDE
Exec=/home/ecgserver2010/AI/pycharm/pycharm-community-2024.3.2/bin/pycharm.sh
Icon=/home/ecgserver2010/AI/pycharm/pycharm-community-2024.3.2/bin/pycharm.png
Terminal=false
Type=Application
Categories=Development;IDE;这里应当使用你自己的PyCharm路径和图标路径
保存并关闭文件,使用 Ctrl + X 保存。
接下来就可以在应用搜索框中找到了:
验证脚本
这里提供了一个验证脚本,你可以先用这个来测试是否能够正常的训练我们的代码。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载数据集
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform
)
# 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x))) # [64, 32, 14, 14]
x = self.pool(torch.relu(self.conv2(x))) # [64, 64, 7, 7]
x = x.view(-1, 64 * 7 * 7) # [64, 3136]
x = torch.relu(self.fc1(x)) # [64, 128]
x = self.dropout(x)
x = self.fc2(x) # [64, 10]
return x
# 初始化模型、损失函数和优化器
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练函数
def train(model, loader, criterion, optimizer):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in tqdm(loader, desc="Training"):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = running_loss / len(loader)
accuracy = 100 * correct / total
return avg_loss, accuracy
# 验证函数
def validate(model, loader, criterion):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(loader, desc="Validating"):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = running_loss / len(loader)
accuracy = 100 * correct / total
return avg_loss, accuracy
# 训练循环
num_epochs = 5
best_accuracy = 0.0
for epoch in range(num_epochs):
print(f"
Epoch {epoch + 1}/{num_epochs}")
# 训练阶段
train_loss, train_acc = train(model, train_loader, criterion, optimizer)
# 验证阶段
val_loss, val_acc = validate(model, test_loader, criterion)
# 保存最佳模型
if val_acc > best_accuracy:
best_accuracy = val_acc
torch.save(model.state_dict(), "best_model.pth")
print(f"Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%")
print(f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%")
print("
Training completed!")
print(f"Best Validation Accuracy: {best_accuracy:.2f}%")
# 测试单个样本
def test_single_sample(model, device):
model.eval()
sample, label = test_dataset[0]
with torch.no_grad():
output = model(sample.unsqueeze(0).to(device))
_, predicted = torch.max(output.data, 1)
print(f"
Sample test:")
print(f"True label: {label}, Predicted: {predicted.item()}")
# 加载最佳模型进行测试
model.load_state_dict(torch.load("best_model.pth"))
test_single_sample(model, device)参考文章
Ubuntu20.04安装Nvidia显卡驱动教程-CSDN博客
深度学习环境搭建入门环境搭建(pytorch版本)_pytorch环境搭建-CSDN博客
在Ubuntu上安装配置pycharm(linux)_ubuntu pycharm-CSDN博客