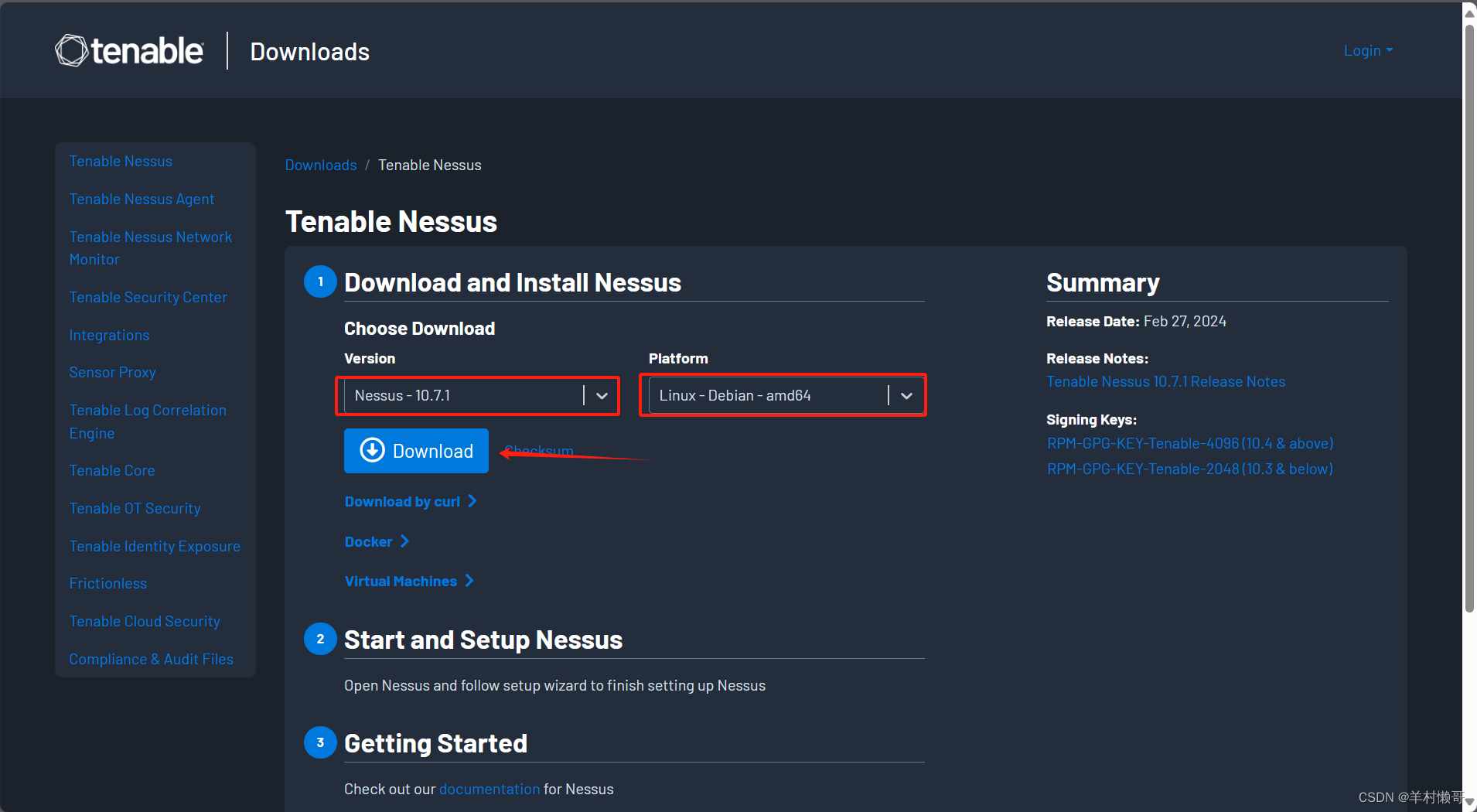
【深度学习】喂饭版-深度学习环境配置(Ubuntu 24.04 + CUDA 12.4 + NVIDIA RTX 3090)
Ubuntu 24.04 + CUDA 12.4 + NVIDIA RTX 3090 深度学习环境配置
阅读提示:文章每一步笔者亲自走了一遍,并安装成功。同时成功运行了ComfyUI下Flux-dev1.0 文生图,最新通义万相Wan2.1文生视频,图生视频。请放心使用。
前提安装NVIDIA驱动,最简便的方法有两种:
第一种:在Ubuntu安装过程中安装NVIDIA驱动:
- 当您启动Ubuntu安装程序时,在安装类型选择界面会有一个选项:“安装Ubuntu时下载更新"和"安装第三方软件用于图形和Wi-Fi硬件,Flash,MP3和其他媒体”。
- 确保勾选"安装第三方软件用于图形和Wi-Fi硬件,Flash,MP3和其他媒体"这个选项。
- 在较新的Ubuntu版本中(如Ubuntu 20.04及以后),选择此选项后可能会出现另一个对话框,询问您是否要安装专有驱动程序,包括NVIDIA驱动。
- 选择"安装"或"是",然后继续正常的安装过程。
- 安装完成并重启后,NVIDIA驱动就已经预先安装好了。
第二种:使用Ubuntu自带的"软件和更新"工具,这是最简单的方法之一:
- 打开"软件和更新"
- 点击"附加驱动"选项卡
- 系统会自动搜索可用的NVIDIA驱动
- 选择推荐的NVIDIA专有驱动,这里选择专属,不要选择开源
- 点击"应用更改"并等待安装完成
- 重启系统
安装步骤
第一步:更新系统
echo "正在更新系统..."
sudo apt update && sudo apt upgrade -y
第二步:安装基础开发工具
echo "正在安装基础开发工具..."
sudo apt install -y build-essential gcc g++ make cmake unzip git wget curl htop
第三步:验证NVIDIA驱动是否已正确安装
echo "验证NVIDIA驱动..."
nvidia-smi
第四步:验证CUDA和NVCC是否已安装
echo "验证CUDA和NVCC..."
nvcc -V
# 如果NVCC未安装,则安装CUDA工具包
if [ $? -ne 0 ]; then
echo "NVCC未安装,正在安装CUDA工具包..."
# 下载CUDA安装包(CUDA 12.4.1)
wget https://developer.download.nvidia.com/compute/cuda/12.4.1_550.54.15/local_installers/cuda_12.4.1_550.54.15_linux.run
# 安装CUDA工具包
sudo sh cuda_12.4.1_550.54.15_linux.run --silent --toolkit
# 删除安装包
rm cuda_12.4.1_550.54.15_linux.run
# 验证安装
nvcc -V
fi
第五步:安装CUDA相关依赖
echo "正在安装CUDA相关依赖..."
# 确保CUDA已正确安装,这里假设CUDA 12.4已安装
# 添加CUDA路径到环境变量
echo 'export PATH=/usr/local/cuda-12.4/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
第六步:安装cuDNN
echo "正在安装cuDNN..."
# 下载cuDNN
wget https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/linux-x86_64/cudnn-linux-x86_64-9.7.1.26_cuda12-archive.tar.xz -O ~/cudnn.tar.xz
# 解压cuDNN
mkdir -p ~/cudnn
tar -xf ~/cudnn.tar.xz -C ~/cudnn
# 复制cuDNN文件到CUDA目录
sudo cp ~/cudnn/cudnn-linux-x86_64-9.7.1.26_cuda12-archive/include/* /usr/local/cuda-12.4/include/
sudo cp ~/cudnn/cudnn-linux-x86_64-9.7.1.26_cuda12-archive/lib/* /usr/local/cuda-12.4/lib64/
sudo chmod a+r /usr/local/cuda-12.4/include/cudnn*.h /usr/local/cuda-12.4/lib64/libcudnn*
# 清理临时文件
rm -rf ~/cudnn ~/cudnn.tar.xz
第七步:安装Python开发环境
echo "正在安装Python开发环境..."
sudo apt install -y python3-dev python3-pip
sudo -H pip3 install --upgrade pip
第八步:创建虚拟环境(推荐使用conda)
echo "正在安装Miniconda..."
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh
bash ~/miniconda.sh -b -p $HOME/miniconda
rm ~/miniconda.sh
echo 'export PATH="$HOME/miniconda/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
# 创建深度学习环境
echo "正在创建深度学习conda环境..."
conda create -n deeplearning python=3.10 -y
conda activate deeplearning
# 在conda环境中安装包
pip install --upgrade pip
第九步:安装深度学习框架和依赖库
echo "正在安装PyTorch和相关库..."
# 安装PyTorch(适用于CUDA 12.4的版本)
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
# 安装TensorFlow(确保安装支持GPU的版本)
pip install tensorflow
# 安装Jupyter生态系统
conda install -y jupyter jupyterlab
# 安装常用的数据科学和机器学习库
conda install -y numpy pandas matplotlib seaborn scikit-learn
# 安装其他有用的深度学习库
pip install transformers -i https://mirrors.aliyun.com/pypi/simple
pip install datasets -i https://mirrors.aliyun.com/pypi/simple
pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple
pip install albumentations -i https://mirrors.aliyun.com/pypi/simple
pip install timm -i https://mirrors.aliyun.com/pypi/simple
pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple
pip install mlflow -i https://mirrors.aliyun.com/pypi/simple
pip install pytorch-lightning -i https://mirrors.aliyun.com/pypi/simple
pip install fastai -i https://mirrors.aliyun.com/pypi/simple
pip install huggingface_hub -i https://mirrors.aliyun.com/pypi/simple
第十步:验证安装
echo "正在验证PyTorch GPU支持..."
python -c "import torch; print('PyTorch版本:', torch.__version__); print('CUDA是否可用:', torch.cuda.is_available()); print('CUDA版本:', torch.version.cuda); print('GPU数量:', torch.cuda.device_count()); print('GPU名称:', torch.cuda.get_device_name(0))"
echo "正在验证TensorFlow GPU支持..."
python -c "import tensorflow as tf; print('TensorFlow版本:', tf.__version__); print('GPU是否可用:', tf.config.list_physical_devices('GPU')); print('列出所有可用GPU:'); [print(gpu) for gpu in tf.config.list_physical_devices('GPU')]"
第十一步:创建简单的深度学习测试脚本
PyTorch测试脚本:
echo "创建PyTorch测试脚本..."
cat > ~/pytorch_test.py << 'EOL'
import torch
import torch.nn as nn
import torch.optim as optim
import time
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 创建一个简单的神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(1000, 2000)
self.fc2 = nn.Linear(2000, 3000)
self.fc3 = nn.Linear(3000, 1000)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 创建模型并移至GPU
model = SimpleNN().to(device)
print("模型已创建并移至", device)
# 创建随机输入数据
batch_size = 64
x = torch.randn(batch_size, 1000).to(device)
y = torch.randn(batch_size, 1000).to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 测试多GPU训练
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 个GPU进行训练!")
model = nn.DataParallel(model)
# 运行训练循环
start_time = time.time()
for epoch in range(10):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/10, Loss: {loss.item():.4f}")
end_time = time.time()
print(f"训练完成! 总用时: {end_time - start_time:.2f} 秒")
EOL
TensorFlow测试脚本:
echo "创建TensorFlow测试脚本..."
cat > ~/tensorflow_test.py << 'EOL'
import tensorflow as tf
import time
import numpy as np
print("TensorFlow版本:", tf.__version__)
print("可用的GPU:", tf.config.list_physical_devices('GPU'))
# 启用内存增长,以防止TensorFlow占用所有GPU内存
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print("设置GPU内存增长模式")
except RuntimeError as e:
print(e)
# 创建一个简单的模型
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(2000, activation='relu', input_shape=(1000,)),
tf.keras.layers.Dense(3000, activation='relu'),
tf.keras.layers.Dense(1000)
])
return model
# 准备随机数据
x = np.random.random((64, 1000)).astype(np.float32)
y = np.random.random((64, 1000)).astype(np.float32)
# 创建和编译模型
model = create_model()
model.compile(optimizer='adam', loss='mse')
# 使用tf.distribute.MirroredStrategy进行多GPU训练
if len(gpus) > 1:
print(f"使用 {len(gpus)} 个GPU进行训练!")
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = create_model()
model.compile(optimizer='adam', loss='mse')
# 训练模型
start_time = time.time()
history = model.fit(x, y, epochs=10, batch_size=64, verbose=1)
end_time = time.time()
print(f"训练完成! 总用时: {end_time - start_time:.2f} 秒")
EOL
第十二步:配置Jupyter Notebook服务器
echo "正在配置Jupyter Notebook服务器..."
# 生成Jupyter配置文件
jupyter notebook --generate-config
# 设置Jupyter密码
python -c "from jupyter_server.auth import passwd; print(passwd())" > ~/.jupyter_password
JUPYTER_PASSWORD=$(cat ~/.jupyter_password)
# 配置Jupyter允许远程访问
cat > ~/.jupyter/jupyter_notebook_config.py << EOL
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.port = 8888
c.NotebookApp.open_browser = False
c.NotebookApp.password = u'${JUPYTER_PASSWORD}'
c.NotebookApp.allow_origin = '*'
c.NotebookApp.notebook_dir = '~/jupyter_notebooks'
EOL
# 创建Jupyter笔记本目录
mkdir -p ~/jupyter_notebooks
# 创建一个演示笔记本
mkdir -p ~/jupyter_notebooks/demos
cat > ~/jupyter_notebooks/demos/gpu_test.ipynb << 'EOL'
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# GPU测试笔记本
",
"
",
"这个笔记本用于测试GPU是否可用于PyTorch和TensorFlow。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## PyTorch GPU测试"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import torch
",
"print(f"PyTorch版本: {torch.__version__}")
",
"print(f"CUDA是否可用: {torch.cuda.is_available()}")
",
"if torch.cuda.is_available():
",
" print(f"CUDA版本: {torch.version.cuda}")
",
" print(f"GPU数量: {torch.cuda.device_count()}")
",
" for i in range(torch.cuda.device_count()):
",
" print(f"GPU {i}: {torch.cuda.get_device_name(i)}")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## TensorFlow GPU测试"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import tensorflow as tf
",
"print(f"TensorFlow版本: {tf.__version__}")
",
"print("可用的GPU:")
",
"gpus = tf.config.list_physical_devices('GPU')
",
"if gpus:
",
" for gpu in gpus:
",
" print(gpu)
",
"else:
",
" print("没有找到GPU")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 简单的PyTorch多GPU测试"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import torch
",
"import torch.nn as nn
",
"import time
",
"
",
"# 创建一个简单的模型
",
"class SimpleModel(nn.Module):
",
" def __init__(self):
",
" super(SimpleModel, self).__init__()
",
" self.layers = nn.Sequential(
",
" nn.Linear(1000, 2000),
",
" nn.ReLU(),
",
" nn.Linear(2000, 1000)
",
" )
",
"
",
" def forward(self, x):
",
" return self.layers(x)
",
"
",
"# 检查GPU可用性并创建模型
",
"device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
",
"model = SimpleModel().to(device)
",
"print(f"使用设备: {device}")
",
"
",
"# 如果有多个GPU,使用DataParallel
",
"if torch.cuda.device_count() > 1:
",
" print(f"使用 {torch.cuda.device_count()} 个GPU进行训练!")
",
" model = nn.DataParallel(model)
",
"
",
"# 创建一些随机数据
",
"batch_size = 128
",
"x = torch.randn(batch_size, 1000).to(device)
",
"
",
"# 测试前向传播速度
",
"start_time = time.time()
",
"for _ in range(100):
",
" with torch.no_grad():
",
" output = model(x)
",
"end_time = time.time()
",
"
",
"print(f"执行100次前向传播用时: {end_time - start_time:.2f} 秒")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
EOL
# 创建Jupyter启动服务脚本
cat > ~/start_jupyter.sh << 'EOL'
#!/bin/bash
source ~/miniconda/bin/activate deeplearning
jupyter notebook
EOL
chmod +x ~/start_jupyter.sh
# 设置开机自启动Jupyter Notebook(可选)
sudo vim /etc/systemd/system/jupyter.service
# 在文件中添加以下内容
# [Unit]
# Description=Jupyter Notebook Server
# After=network.target
# [Service]
# Type=simple
# User=oldbird
# ExecStart=/bin/bash /home/oldbird/start_jupyter.sh
# Restart=on-failure
# RestartSec=5s
# [Install]
# WantedBy=multi-user.target
# 重新加载systemd服务:
sudo systemctl daemon-reload
# 启用服务,使其在开机时自动启动:
sudo systemctl enable jupyter.service
# 立即启动服务
sudo systemctl start jupyter.service
# 检查服务状态
sudo systemctl status jupyter.service
安装完成
测试环境
# 测试基本深度学习环境
conda activate deeplearning
python ~/pytorch_test.py
python ~/tensorflow_test.py
# 启动Jupyter Notebook服务器:
~/start_jupyter.sh
然后在浏览器访问 http://你的IP地址:8888