机器学习模型部署:使用Flask 库的 Python Web 框架将XGBoost模型部署在服务器上(简单小模型)从模型训练到部署再到本地调用
1.XGBoost模型训练预测风速模型
2.保存训练好的模型
3.服务器端部署及运行
4.本地PyCharm调用
5.一些报错问题及注意
一、XGBoost模型训练预测风速模型
这里不解释代码,后面其他文章说明,使用了贝叶斯优化寻找最佳参数组合。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor # 导入 XGBoost 回归模型
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import optuna
import joblib
import pickle
# 1. 加载数据
data1 = pd.read_csv(r'ID01.csv')
# 2. 确保 date_time 列是 datetime 类型
data1['date_time'] = pd.to_datetime(data1['date_time'], format='%Y/%m/%d %H:%M')
# 3. 添加滞后特征
lags = 9 # 滞后步长为 12
for lag in range(1, lags + 1):
data1[f'wind_obs_lag_{lag}'] = data1['wind_obs'].shift(lag)
lags1 = 9 # 滞后步长为 12
for lag in range(1, lags1 + 1):
data1[f'ec_lag_{lag}'] = data1['ec'].shift(lag)
# 4. 添加滑动窗口特征
window_size = 12 # 滑动窗口大小
data1['wind_obs_rolling_mean'] = data1['wind_obs'].shift(1).rolling(window=window_size, min_periods=1).mean() # 滑动平均值
data1['wind_obs_rolling_std'] = data1['wind_obs'].shift(1).rolling(window=window_size, min_periods=1).std() # 滑动标准差
data1['wind_obs_rolling_max'] = data1['wind_obs'].shift(1).rolling(window=window_size, min_periods=1).max() # 最大值
data1['wind_obs_rolling_min'] = data1['wind_obs'].shift(1).rolling(window=window_size, min_periods=1).min() # 最小值
window_size1 = 12 # 滑动窗口大小
data1['ec_mean'] = data1['ec'].shift(1).rolling(window=window_size1, min_periods=1).mean() # 滑动平均值
data1['ec_std'] = data1['ec'].shift(1).rolling(window=window_size1, min_periods=1).std() # 滑动标准差
data1['ec_max'] = data1['ec'].shift(1).rolling(window=window_size1, min_periods=1).max() # 最大值
data1['ec_min'] = data1['ec'].shift(1).rolling(window=window_size1, min_periods=1).min() # 最小值
# 5. 定义时间范围并筛选数据
start_time = '2023-06-01 00:00:00'
end_time = '2024-06-30 18:00:00'
data1 = data1[(data1['date_time'] >= start_time) & (data1['date_time'] <= end_time)]
# 6. 按时间顺序划分数据集
train_start = '2023-06-01 00:00:00'
train_end = '2024-05-31 18:00:00'
test_start = '2024-06-01 00:00:00'
test_end = '2024-06-30 18:00:00'
train_data = data1[(data1['date_time'] >= train_start) & (data1['date_time'] <= train_end)]
test_data = data1[(data1['date_time'] >= test_start) & (data1['date_time'] <= test_end)]
# 7. 数据预处理
# 提取时间特征
for data in [train_data, test_data]:
data.loc[:, 'hour'] = data['date_time'].dt.hour
data.loc[:, 'day'] = data['date_time'].dt.day
data.loc[:, 'month'] = data['date_time'].dt.month
data.loc[:, 'year'] = data['date_time'].dt.year
# 提取季节特征
def get_season(month):
if month in [3, 4, 5]:
return 'Spring'
elif month in [6, 7, 8]:
return 'Summer'
elif month in [9, 10, 11]:
return 'Autumn'
else:
return 'Winter'
data.loc[:, 'season'] = data['month'].apply(get_season)
season_mapping = {'Spring': 1, 'Summer': 2, 'Autumn': 3, 'Winter': 4}
data.loc[:, 'season'] = data['season'].map(season_mapping)
# 8. 提取特征和目标列
X_train = train_data[['ec', 'hour', 'day', 'month', 'year', 'season'] + [f'wind_obs_lag_{lag}' for lag in range(1, lags + 1)] + [f'ec_lag_{lag}' for lag in range(1, lags + 1)] + ['wind_obs_rolling_mean', 'wind_obs_rolling_std', 'wind_obs_rolling_max', 'wind_obs_rolling_min'] +['ec_mean', 'ec_std', 'ec_max', 'ec_min']]
y_train = train_data['wind_obs']
X_test = test_data[['ec', 'hour', 'day', 'month', 'year', 'season'] + [f'wind_obs_lag_{lag}' for lag in range(1, lags + 1)] + [f'ec_lag_{lag}' for lag in range(1, lags + 1)] + ['wind_obs_rolling_mean', 'wind_obs_rolling_std', 'wind_obs_rolling_max', 'wind_obs_rolling_min'] +['ec_mean', 'ec_std', 'ec_max', 'ec_min']]
y_test = test_data['wind_obs']
# 9. 数据归一化(最大最小归一化)
scaler = MinMaxScaler()
y_scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
y_train_scaled = y_scaler.fit_transform(y_train.values.reshape(-1, 1)).flatten()
y_test_scaled = y_scaler.transform(y_test.values.reshape(-1, 1)).flatten()
# 8. 定义 Optuna 目标函数
def objective(trial):
# 定义超参数搜索范围
n_estimators = trial.suggest_int('n_estimators', 50, 700)
learning_rate = trial.suggest_float('learning_rate', 0.01, 0.2)
max_depth = trial.suggest_int('max_depth', 3, 30)
min_child_weight = trial.suggest_int('min_child_weight', 1, 10)
subsample = trial.suggest_float('subsample', 0.5, 1.0)
colsample_bytree = trial.suggest_float('colsample_bytree', 0.5, 1.0)
# 构建 XGBoost 回归模型
xgb = XGBRegressor(
n_estimators=n_estimators,
learning_rate=learning_rate,
max_depth=max_depth,
min_child_weight=min_child_weight,
subsample=subsample,
colsample_bytree=colsample_bytree,
random_state=42,
n_jobs=-1
)
# 训练和评估模型
xgb.fit(X_train_scaled, y_train_scaled)
y_pred = xgb.predict(X_test_scaled)
rmse = np.sqrt(mean_squared_error(y_test_scaled, y_pred))
return rmse
# 10. 运行 Optuna 优化
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=500)
# 获取最佳超参数
best_params = study.best_params
print("最佳超参数:", best_params)
# 11. 使用最佳超参数训练模型
best_model = XGBRegressor(
n_estimators=best_params['n_estimators'],
learning_rate=best_params['learning_rate'],
max_depth=best_params['max_depth'],
min_child_weight=best_params['min_child_weight'],
subsample=best_params['subsample'],
colsample_bytree=best_params['colsample_bytree'],
random_state=42
#n_jobs=-1
)
best_model.fit(X_train_scaled, y_train_scaled)
# 12. 预测
y_train_pred = best_model.predict(X_train_scaled)
y_test_pred = best_model.predict(X_test_scaled)
# 反归一化
y_train_pred = y_scaler.inverse_transform(y_train_pred.reshape(-1, 1)).flatten()
y_test_pred = y_scaler.inverse_transform(y_test_pred.reshape(-1, 1)).flatten()
# 13. 评估指标
def evaluate(y_true, y_pred, dataset_name):
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
mae = mean_absolute_error(y_true, y_pred)
mbe = np.mean(y_pred - y_true) # Mean Bias Error
r2 = r2_score(y_true, y_pred)
print(f"{dataset_name} RMSE: {rmse:.4f}")
print(f"{dataset_name} MAE: {mae:.4f}")
print(f"{dataset_name} MBE: {mbe:.4f}")
print(f"{dataset_name} R2 Score: {r2:.4f}")
# 输出训练集和测试集的评价指标
evaluate(y_train, y_train_pred, "Training Set")
evaluate(y_test, y_test_pred, "Test Set")
# 14. 可视化
# 绘制训练集和测试集的观测值与预测值散点图
plt.figure(figsize=(12, 6))
plt.scatter(y_test, y_test_pred, alpha=0.5, label='Test Set')
plt.scatter(y_train, y_train_pred, alpha=0.5, label='Training Set')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--', label='Ideal Line')
plt.xlabel('Observed Wind Speed')
plt.ylabel('Predicted Wind Speed')
plt.title('Observed vs Predicted Wind Speed')
plt.legend()
plt.grid(True)
plt.show()
# 15. 可视化预测结果
# 绘制测试集的实际值和预测值曲线
plt.figure(figsize=(12, 6))
plt.plot(y_test, label='Observed', color='blue')
plt.plot(y_test_pred, label='Predicted', color='red')
plt.legend()
plt.title('Observed vs Predicted Wind Speed (Test Set)')
plt.xlabel('Time')
plt.ylabel('Wind Speed')
plt.grid(True)
plt.show()
# 绘制训练集的实际值和预测值曲线
plt.figure(figsize=(12, 6))
plt.plot(y_train, label='Observed', color='blue')
plt.plot(y_train_pred, label='Predicted', color='red')
plt.legend()
plt.title('Observed vs Predicted Wind Speed (Training Set)')
plt.xlabel('Time')
plt.ylabel('Wind Speed')
plt.grid(True)
plt.show()
# 16. 输出特征重要性
# 获取特征名称
feature_names = X_train.columns
# 获取特征重要性
feature_importances = best_model.feature_importances_
# 将特征名称与重要性对应起来
feature_importance = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importances})
# 按重要性排序,以查看最重要的特征
feature_importance = feature_importance.sort_values(by='Importance', ascending=False)
# 输出特征重要性
print("特征重要性:")
print(feature_importance)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['Feature'], feature_importance['Importance'], color='skyblue')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance')
plt.show()
# 17. 保存模型和预处理对象
# 使用 joblib 保存模型
joblib.dump(best_model, 'xgb_wind_speed_model.joblib')
# 使用 pickle 保存模型(另一种方式)
with open('xgb_wind_speed_model.pkl', 'wb') as f:
pickle.dump(best_model, f)
# 保存 scaler 对象(以便后续对新数据进行相同的预处理)
joblib.dump(scaler, 'scaler.joblib')
joblib.dump(y_scaler, 'y_scaler.joblib')
print("模型和预处理对象已保存")
二、保存训练好的模型
这里我直接把代码合一起,所有结束在文件下生成四个文件。这里名称我后面修改了
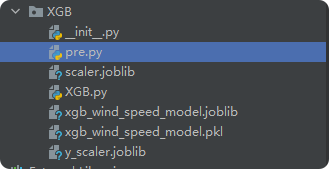
三、服务器端部署
要将训练好的XGBoost模型部署在服务器上并在本地PyCharm调用,你可以使用Flask或FastAPI创建一个简单的Web服务。
1. 创建服务器端项目结构(PyCharm下新建文件夹model_api)
按之前文件修改名字和创建新文件。
model_api/
│
├── app.py # 主应用文件
├── requirements.txt # 依赖文件
├── models/
│ ├── xgb_model.joblib # 保存的模型文件
│ ├── scaler.joblib # 特征缩放器
│ └── y_scaler.joblib # 目标变量缩放器
2.创建Flask API (app.py)
这个后面是在服务器中运行,遇到好几次报错,最后统一说明。
from flask import Flask, request, jsonify
import joblib
import numpy as np
import pandas as pd
from datetime import datetime
from sklearn.preprocessing import MinMaxScaler
app = Flask(__name__)
# 加载模型和预处理对象
model = joblib.load('models/xgb_model.joblib')
scaler = joblib.load('models/scaler.joblib')
y_scaler = joblib.load('models/y_scaler.joblib')
# 定义与训练时相同的参数
lags = 9 # 滞后步长
window_size = 12 # 滑动窗口大小
def prepare_features(input_data):
"""准备特征,与训练时完全相同的预处理步骤"""
# 将输入数据转换为DataFrame
data = pd.DataFrame([input_data])
# 解析日期时间
data['date_time'] = pd.to_datetime(data['date_time'])
data['hour'] = data['date_time'].dt.hour
data['day'] = data['date_time'].dt.day
data['month'] = data['date_time'].dt.month
data['year'] = data['date_time'].dt.year
# 季节特征
def get_season(month):
if month in [3, 4, 5]:
return 'Spring'
elif month in [6, 7, 8]:
return 'Summer'
elif month in [9, 10, 11]:
return 'Autumn'
else:
return 'Winter'
data['season'] = data['month'].apply(get_season)
season_mapping = {'Spring': 1, 'Summer': 2, 'Autumn': 3, 'Winter': 4}
data['season'] = data['season'].map(season_mapping)
# 添加滞后特征 - 这些值应该由客户端提供
for lag in range(1, lags + 1):
if f'wind_obs_lag_{lag}' not in data.columns:
raise ValueError(f"Missing required feature: wind_obs_lag_{lag}")
if f'ec_lag_{lag}' not in data.columns:
raise ValueError(f"Missing required feature: ec_lag_{lag}")
# 添加滑动窗口特征 - 这些值应该由客户端计算后提供
window_features = [
'wind_obs_rolling_mean', 'wind_obs_rolling_std',
'wind_obs_rolling_max', 'wind_obs_rolling_min',
'ec_mean', 'ec_std', 'ec_max', 'ec_min'
]
for feature in window_features:
if feature not in data.columns:
raise ValueError(f"Missing required window feature: {feature}")
# 选择模型需要的所有特征列
features = [
'ec', 'hour', 'day', 'month', 'year', 'season'
] + [f'wind_obs_lag_{lag}' for lag in range(1, lags + 1)]
+ [f'ec_lag_{lag}' for lag in range(1, lags + 1)]
+ [
'wind_obs_rolling_mean', 'wind_obs_rolling_std',
'wind_obs_rolling_max', 'wind_obs_rolling_min',
'ec_mean', 'ec_std', 'ec_max', 'ec_min'
]
# 确保所有特征都存在
missing_features = [f for f in features if f not in data.columns]
if missing_features:
raise ValueError(f"Missing features: {missing_features}")
# 缩放特征
features_scaled = scaler.transform(data[features])
return features_scaled
@app.route('/predict', methods=['POST'])
def predict():
"""预测端点"""
try:
# 获取JSON数据
data = request.get_json()
# 准备特征
features = prepare_features(data)
# 预测
prediction_scaled = model.predict(features)
# 反归一化
prediction = y_scaler.inverse_transform(prediction_scaled.reshape(-1, 1))[0][0]
# 返回结果
return jsonify({
'prediction': float(prediction), # 转换为Python原生float类型
'status': 'success'
})
except ValueError as e:
return jsonify({
'error': str(e),
'status': 'error',
'message': '缺少必要的特征字段,请确保提供所有滞后特征和滑动窗口特征'
}), 400
except Exception as e:
return jsonify({
'error': str(e),
'status': 'error'
}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)
3.创建 requirements.txt
这个文本用途是安装项目所需的所有依赖包,罗列了项目所需的所有 Python 包及其版本号,这个报错好几次,主要原因是服务器端和本地端安装库版本不一致。。
flask==3.1.0
joblib==1.4.2
numpy==1.24.3
pandas==2.0.3
scikit-learn==1.3.2
xgboost==2.1.1
4. 部署到服务器及运行
1.将整个项目文件夹上传到服务器
把之前model_api文件夹上传到服务器中。
2.在服务器上创建虚拟环境并安装依赖
这就使用到了requirements.txt这个文件作用,装起来很快。
#1. conda创建虚拟环境/也可以python创建环境,环境名WY
(base)$ conda create --name WY python=3.9
# 环境创建中输入y安装几个包
#2.激活环境
(base)$ conda activate WY
#3.安装依赖包
pip install -r requirements.txt
5.运行服务
python app.py
当然这里报了几次错误,后面说。这里给出运行成功截图。还有警告
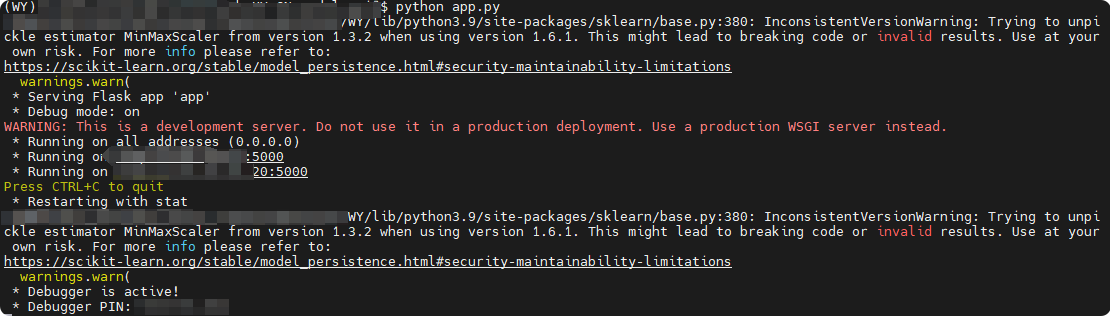
四、本地PyCharm调用
1. 创建客户端代码 (client.py)
这里都是我给的值,真的预测通过CSV输入数据。
代码最后有个服务器给的URL是多少
import requests
import json
from datetime import datetime
# 示例数据 - 客户端需要计算所有滞后和滑动窗口特征
sample_data = {
"date_time": "2024-06-01 12:00:00",
"ec": 5.3,
"hour": 12,
"day": 1,
"month": 6,
"year": 2024,
"season": 2,
# 滞后特征
"wind_obs_lag_1": 4.8,
"wind_obs_lag_2": 4.5,
"wind_obs_lag_3": 4.2,
"wind_obs_lag_4": 4.0,
"wind_obs_lag_5": 3.9,
"wind_obs_lag_6": 3.8,
"wind_obs_lag_7": 3.7,
"wind_obs_lag_8": 3.6,
"wind_obs_lag_9": 3.5,
"ec_lag_1": 5.1,
"ec_lag_2": 5.0,
"ec_lag_3": 4.9,
"ec_lag_4": 4.8,
"ec_lag_5": 4.7,
"ec_lag_6": 4.6,
"ec_lag_7": 4.5,
"ec_lag_8": 4.4,
"ec_lag_9": 4.3,
# 滑动窗口特征
"wind_obs_rolling_mean": 4.2,
"wind_obs_rolling_std": 0.5,
"wind_obs_rolling_max": 5.0,
"wind_obs_rolling_min": 3.5,
"ec_mean": 4.8,
"ec_std": 0.3,
"ec_max": 5.2,
"ec_min": 4.5
}
response = requests.post(
"http://123.45.67.8:5000/predict",%这里看你服务器给的URL是多少
headers={"Content-Type": "application/json"},
data=json.dumps(sample_data)
)
print(response.json())
2. 在PyCharm中运行客户端
在PyCharm中创建新项目
添加client.py文件
确保安装了requests库 (PyCharm通常会自动提示安装)
运行客户端代码
成功的链接的截图我这边开了VPN需保证在同一网络。
服务器端

本地端

五、一些报错问题和注意
1.服务器端运行app.py报错,弄清楚版本号。
这部分报错问题
(1)于 Flask 和 Werkzeug 的版本不兼容导致的
pip install --upgrade Flask Werkzeug
(2)模型文件的格式与当前 XGBoost 版本不兼容
核对两个版本,重新安装库
pip install xgboost==2.1.1
(3)继续报错更新其他库
pip install --upgrade joblib numpy scikit-learn