【标注工具】Ubuntu20.04 下 CVAT 的安装及使用教程
一、背景
随着数据量和应用场景的增加,本人在数据标注的路上一去不复返,经常是一杯茶一包烟,一批数据标几天。作为一项枯燥无聊,流水线化的工作,却是深度(监督)学习至关重要的一环,标注数据质量的好坏直接影响模型学习效果。为了提升标注效率,就得找一些自动或半自动的标注工具,网上一搜有很多[1-2],最终选了 CVAT 这款工具。CVAT 支持图像和视频标注,多种标注任务和丰富的标签格式,也支持使用自己训练的模型进行自动化标注,但不好的地方在于安装过程稍显复杂(实际最难的是网络环境导致的各种安装失败),因此特意记录一下。
二、安装教程
CVAT 支持在线和离线两种方式,在线方式使用比较简单,进入官网注册后就可以标注了,免费用户有数据限制,如果数据量大可能需要购买会员;离线方式则是完全免费使用,无数据限制,本文主要介绍 CVAT 的离线方式(本地化部署)。
首先放上官方代码库和安装教程
https://github.com/cvat-ai/cvat
Installation Guide | CVAT
1. Docker 安装
CVAT 使用 Docker 安装,如果是第一次使用,需要安装 Docker 和 Docker Compose,输入以下命令:
sudo apt-get update
sudo apt-get --no-install-recommends install -y
apt-transport-https
ca-certificates
curl
gnupg-agent
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository
"deb [arch=amd64] https://download.docker.com/linux/ubuntu
$(lsb_release -cs)
stable"
sudo apt-get update
sudo apt-get --no-install-recommends install -y
docker-ce docker-ce-cli containerd.io docker-compose-plugin如果安装失败,需要更换 apt 源[3],Ubuntu24.04 之前的版本,将 /etc/apt/sources.list 备份后,把其中的内容替换为以下内容:
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted ,universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
2. 提升权限(可选)
为了避免每次使用 sudo 运行 docker 命令,可以创建一个名为 docker 的 Unix 组,并将当前用户添加到该组中:
sudo groupadd docker
sudo usermod -aG docker $USER重新登录即可关联用户,输入 groups 命令可以查看是否成功添加用户。

3. 克隆源码
运行以下命令克隆最新源码:
git clone https://github.com/cvat-ai/cvat如果克隆失败可以到 github 官方仓库里下载 zip 包并解压到本地。
之后 cd 到安装目录
cd cvat4. 多用户使用(可选)
如果要跨网或跨设备访问(团队协作中会用到),需要添加环境变量:
export CVAT_HOST=FQDN_or_YOUR-IP-ADDRESSFQDN 是你的网站域名,或者使用本机 ip。
5. 运行 Docker
输入以下命令下载最新的 CVAT 和其他所需镜像(如 postgres、redis)并启动容器,注意这步最耗时,推荐使用 VPN 下载,如果失败可以多试几次。
docker compose up -d
第一次运行时拉取镜像失败,报如下错误
docker: Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers).
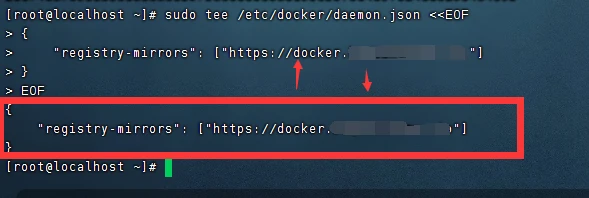
在 /etc/docker 下新建 daemon.json,添加以下内容[4]:
{
"registry-mirrors": ["https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"]
}重启 Docker
systemctl daemon-reload
systemctl restart docker指定版本(可选)
使用 CVAT_VERSION 环境变量指定要安装特定版本的 CVAT 版本(例如v2.1.0,dev)。
CVAT_VERSION=dev docker compose up -d6. 用户注册
创建一个超级用户,超级用户拥有查看任务列表、为用户分配正确的组等权限
docker exec -it cvat_server bash -ic 'python3 ~/manage.py createsuperuser'
7. 启动
打开浏览器并转到 localhost:8080 即可打开登录界面,输入之前创建的超级用户名和密码即可登入使用。

8. 关闭
停止并移除所有容器,重新启动时运行步骤5。运行 CVAT 还是挺吃资源的,不用的时候最好是关掉服务,用的时候再重新打开。
docker compose down9. 删除
如果想要删除 CVAT 镜像,首先执行步骤8关闭 CVAT 服务,再删除镜像。
输入 docker images 查看所有镜像

找到 CVAT 有关的镜像并删除(根据 IMAGE ID 前三位删除即可)
docker rmi a96注:Google Chrome 是 CVAT 唯一支持的浏览器。
10. Windows 安装
Windows 安装 CVAT 比较麻烦,第一次使用 CVAT 就是在 Windows 上,当时折腾了两天才用起来,需要安装的东西多,由于时间较长,具体折腾的细节已经忘了。参考官方文档,需要安装 WSL2、Docker Desktop、Git,这几个配置好了,后面的安装跟 Linux 大差不差,如果由于网络问题安装失败,切记挂 VPN 并多试几次。
三、使用教程
安装完成后就可以导入数据进行标注了,下面只介绍主要功能,其它细节和参数设置可参考官方说明文档。
1. 主界面
主要用到的几个板块:项目Projects、任务Tasks、作业Jobs、请求Requests。
2. 新建项目(Projects)
根据任务需求新建一个项目
- Name:填写项目名称
- Labels:创建labels,labels包含两种格式,Raw和Constructor,选择Constructor格式,可以设置标签名、形状、颜色和属性。
- Advanced configuration:高级选项,具体可参考官方文档
- Submit & Open:完成创建
- Submit & Continue:继续创建
3. 创建任务(Tasks)
可以选择创建一个或多个任务
创建任务界面(Multi)
- Name:任务名,默认使用原文件名,可以修改,比如添加编号等
- Project:所属项目,如果有创建项目则选择任务对应的项目,没有可不填
- Subset:所属数据集,train/val/test
- Labels:自动使用所属项目中的标签,没有项目则需要创建标签
- Select files:导入数据,可以批量导入
- Advanced configuration、Quality:高级选项,具体可参考官方文档
上传进度

上传完成后的任务界面
点击 Open 进入任务详情页

可以看到任务的创建时间、任务状态、任务阶段、帧数等信息,其它详细说明可参考官方文档。
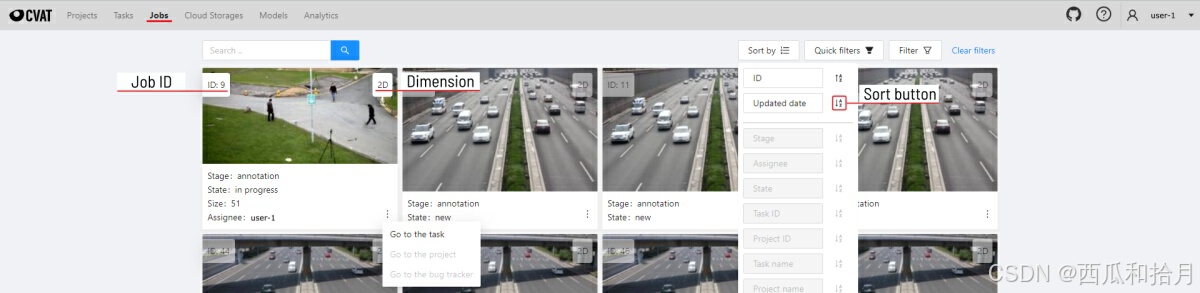
4. 作业页面(Jobs)
此页面列出所有作业的信息,可以点击某个作业进入标注页面,一个任务可以对应一个或多个作业,其它详细说明可参考官方文档。
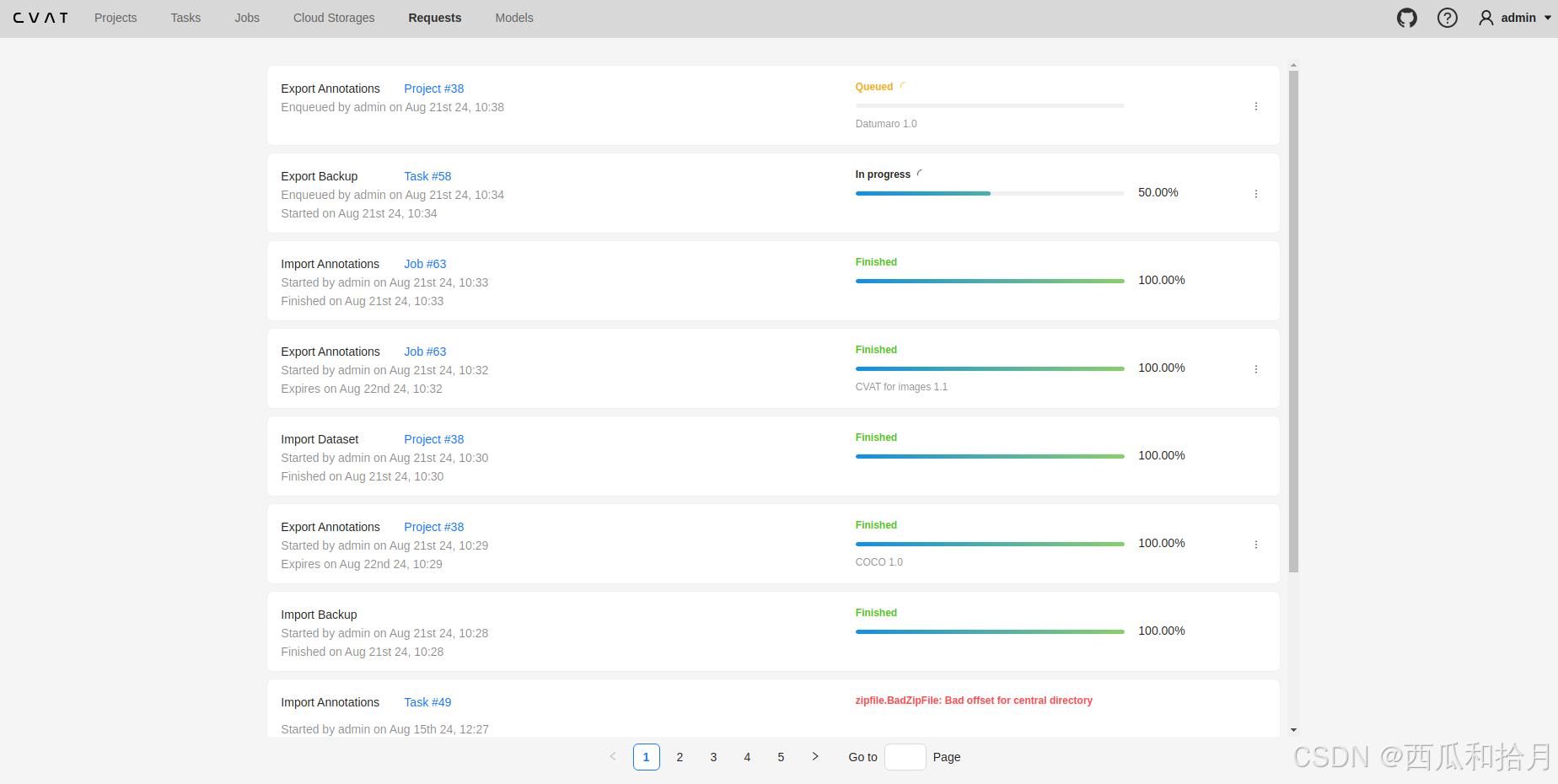
5. 请求页面(Requests)
此页面会列出所有数据导入或导出的进度及状态信息。如果是导出标签数据,可在到处进度完成后进行下载。
6. 标注页面
主要包含四部分:菜单及导航栏、控件侧边栏、目标侧边栏和工作区。
6.1 菜单及导航栏
6.1.1 菜单Menu
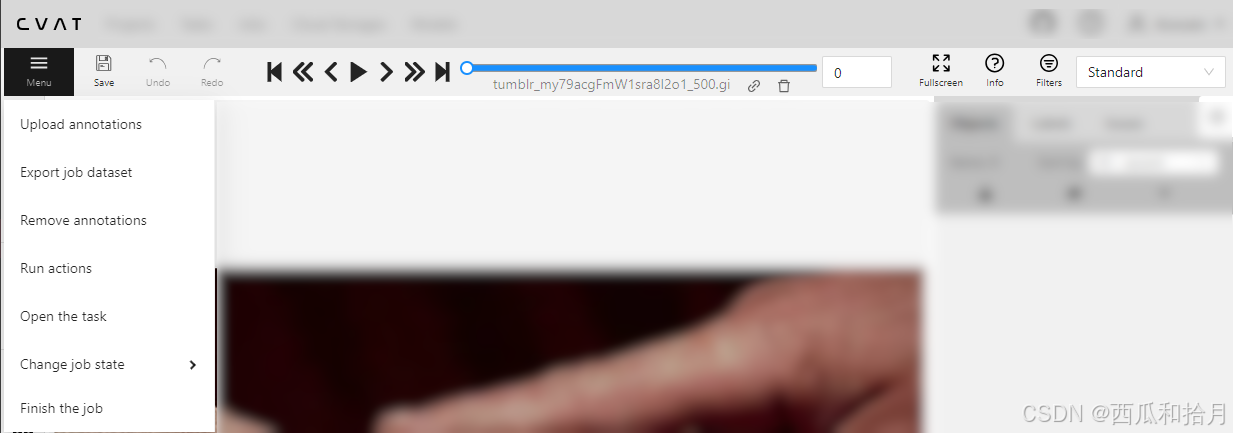
- Upload annotations:上传标注文件到当前任务
- Export job dataset:导出数据集,支持多种格式(COCO、PASCAL VOC、YOLO、Labelme等,最新支持YOLOv8)
- Remove annotations:删除标注信息,全部删除或部分删除
- Run actions:在标注数据上执行标注行为(形状转换),具体没用过,可看说明文档
- Open the task:打开任务的详细页面
- Change job states:改变作业状态(新创建or进行中or拒绝作业or完成)
- Finish the job:保存标注并标记完成。
其它按钮说明可参考说明文档
6.1.2 控制条
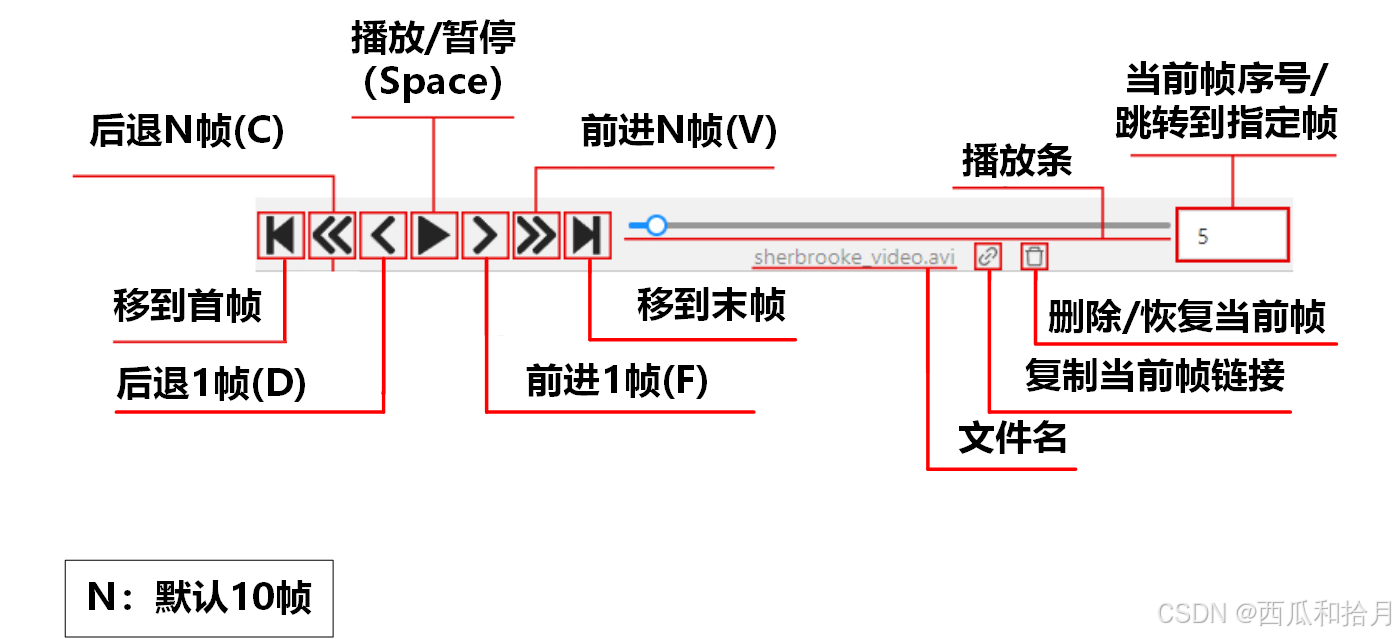
6.2 控件侧边栏
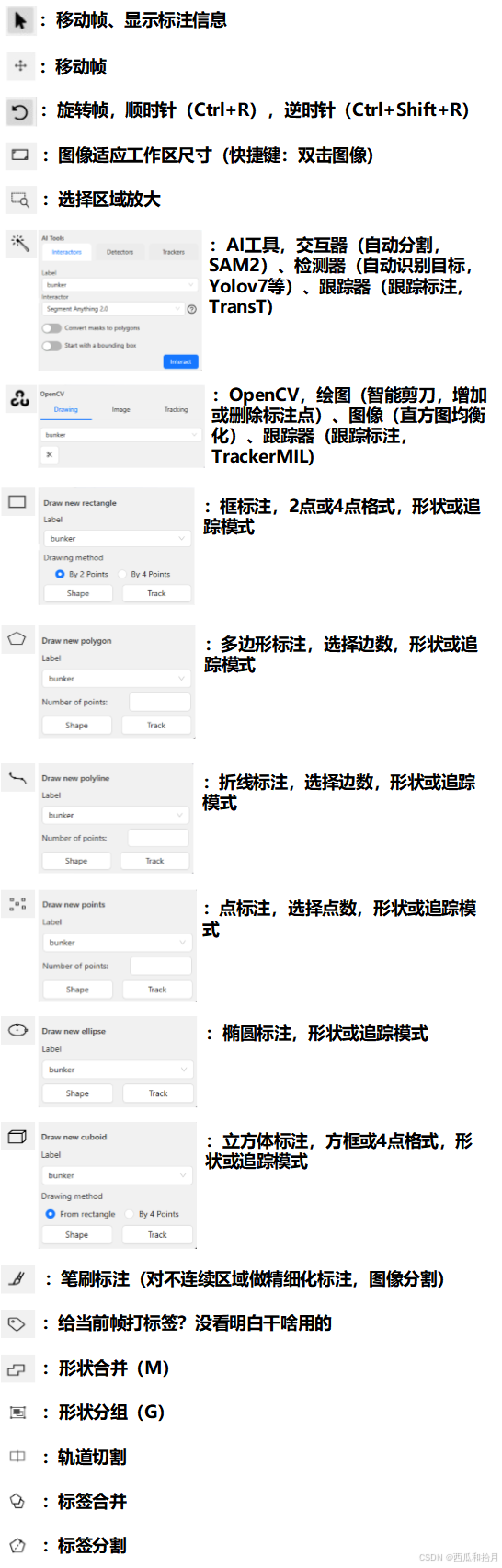
后面几个没用过,也没看明白咋用的,好像都是分割用的,以后用到再说吧。官方文档。
6.3 目标侧边栏
显示当前帧中包含的所有目标和对应的标签信息,可以对目标进行过滤、排序,变更标签、复制标签,隐藏标注,锁定标签,改变标签颜色、透明度等等。官方文档。
6.4 工作区
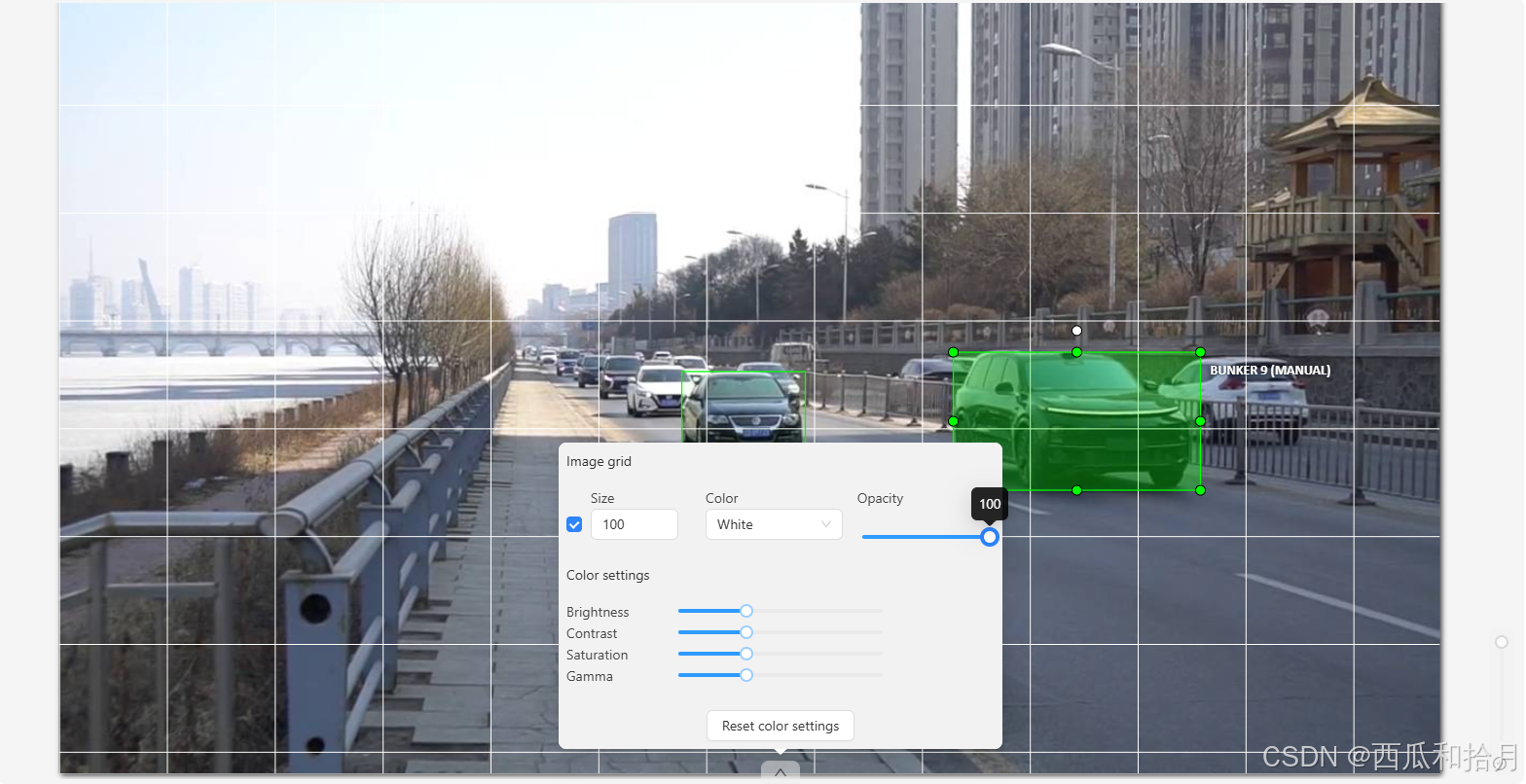
标注区域,可添加图像网格,设置网格透明度,调整图像亮度、对比度、饱和度、gamma值等。 官方文档。
7. 跟踪模式(Track)
如果目标位置连续变动,可以使用跟踪模式进行标注。选定起始关键帧和结束关键帧并标注,之后重新退回起始关键帧并移动至结束关键帧,在这之间的帧将使用目标跟踪对同一目标进行自动标注,使用控制条中的前进/后退帧按钮逐帧检查,人工微调即可,一定程度上提高了标注效率。官方文档。

8. 自动标注
CVAT 支持使用预训练模型进行自动标注,模型来源支持三种方式:
- 预装模型(face-detection-0205,RetinaNet R101,Text detection,YOLOv3,YOLOv7)
- 集成自Hugging Face 或 Roboflow 的模型(仅支持在线标注方式)
- 使用Nuclio部署的自训练模型
本文只介绍第三种私有部署的方式,使用自己的模型标注自己的数据。
8.1 环境配置
8.1.1 重启容器
要使用自动标注功能,首先不要使用 docker compose up 的启动方式,使用 docker compose down 关闭之前开启的容器。
在 CVAT 根目录下运行以下命令重新开启容器:
docker compose -f docker-compose.yml -f components/serverless/docker-compose.serverless.yml up -d相应的关闭容器命令:
docker compose -f docker-compose.yml -f components/serverless/docker-compose.serverless.yml down8.1.2 安装nuctl
docker-compose.serverless.yml 文件中指定的nuctl版本为 1.13.0,使用 wget 安装:
wget https://github.com/nuclio/nuclio/releases/download/1.13.0/nuctl-1.13.0-linux-amd64如果安装失败可以到 GitHub 手动下载到本地(CVAT 根目录下)。
下载完成后赋予其执行权限并创建软链接:
sudo chmod +x nuctl--linux-amd64
sudo ln -sf $(pwd)/nuctl--linux-amd64 /usr/local/bin/nuctl 8.1.3 部署功能
需要确保先使用 8.1.1 中的方式开启容器,之后运行以下命令:
./serverless/deploy_cpu.sh serverless/openvino/dextr
./serverless/deploy_cpu.sh serverless/openvino/omz/public/yolo-v3-tf如果安装报错:

则运行以下命令安装 buildx:
sudo apt-get install docker-buildx-plugin
安装成功后重新执行 8.1.3,再次报错,无法访问 gcr.io
解决方法
配置完成后再次执行 8.1.3,安装过程很长,需要保证网络稳定。
安装完成后可以打开nuclio面板查看刚才部署的模型,状态为正常运行。

8.2 运行示例
环境配置好之后,进入我们的任务界面,选择 automatic annotation,此时就会出现我们之前部署好的模型,标签映射完成后点击 Annotate 就可以开始自动标注了。



完成之后打开看一下,大部分目标已标出,因为只做了一次标签映射(car-->car),所以模型应该只检测了 car 而没有检测大巴车(bus),其它个别误检的地方人工删除即可。
8.3 添加 GPU 支持
将模型放到GPU上加速运行
8.3.1 安装 NVIDIA Container Toolkit
(1)需要先确保系统中安装了 NVIDIA 驱动和 Docker;
(2)配置工具仓库;
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list(3)配置仓库以使用实验性工具包;
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list(4)更新 apt;
sudo apt-get update(5)安装 NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
8.3.2 配置 NVIDIA Container Toolkit
(1)配置容器 runtime
sudo nvidia-ctk runtime configure --runtime=docker(2)重启 Docker
sudo systemctl restart docker8.3.3 验证 NVIDIA Container Toolkit
运行一个 CUDA 容器验证安装:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi输出如下内容证明安装成功
测试代码
image=$(curl https://upload.wikimedia.org/wikipedia/en/7/7d/Lenna_%28test_image%29.png --output - | base64 | tr -d '
')
cat << EOF > /tmp/input.json
{"image": "$image"}
EOF
cat /tmp/input.json | nuctl invoke openvino-omz-public-yolo-v3-tf -c 'application/json'
8.3.4 运行
实际运行的话应该是使用以下命令,重新部署GPU端的功能,实际没有试过。同级目录下有deploy_cpu.sh 和 deploy_gpu.sh 两个文件。
./serverless/deploy_gpu.sh serverless/openvino/dextr
./serverless/deploy_gpu.sh serverless/openvino/omz/public/yolo-v3-tf8.4 添加自己的预训练模型
官方文档里给出的示例是部署 Detectron2 中的模型,虽然模型挺丰富,但如果是要标注私有数据集,那还是得部署自己的模型,这就比较麻烦了,需要建立本地镜像,修改配置文件,写推理脚本。本节主要参考[8]。大佬给出的例子是基于yolov5 的,恰巧本人的预训练模型也是基于 yolov5 的,如果是其它模型,修改思路应该大差不差。
8.4.1 建立本地镜像
本步骤默认本地已有自己的代码库并已经训练好了自己的模型,如果没有就 git clone 再训练吧。
在 cvat/serverless 下按照官方已有的文件路径新建自己的模型和文件路径,比如使用 pytorch 训练的基于 yolov5 的用于检测人脸的模型,可以在 cvat/serverless/pytorch 下新建custom/facedet/nuclio 路径,在该路径下创建 Dockerfile 用于建立基础镜像,内容如下:
FROM ultralytics/yolov5:latest # yolov5官方镜像
RUN mkdir -p /opt/nuclio # 创建工作目录,该路径是CVAT默认工作路径,必须有
WORKDIR /opt/nuclio # 指定工作目录
COPY . /opt/nuclio # 复制当前路径下所有的文件到docker中
最后一行我在执行过程中会报错,因此改为手动 cp 到 /opt/nuclio 下即可。
之后运行以下命令建立镜像,不要漏掉后面的空格和“.”。
docker build -t {docker name}:{tag} -f Dockerfile .
docker images 查看基础镜像是否创建成功

8.4.2 创建部署文件
在当前路径下新建几个文件:function.yaml、function-gpu.yaml(可以不要,用于GPU加速的)、main.py、model_handler.py,同时将自己的模型文件拿过来。
最终的文件结构如下:

(1)function.yaml 文件
nuclio 工具的配置文件,用于部署预训练模型到 CVAT,nuclio 将预训练模型作为 serverless function 部署到 CVAT,可以理解为 nuclio 为预训练创建了一个可以接入到 cvat 的 docker 镜像+容器,建立镜像的过程是通过 function.yaml 配置的。创建内容如下:
metadata:
name: pth-facebookresearch-detectron2-retinanet-r101 # CVAT的function名称
namespace: cvat
annotations:
name: RetinaNet R101 # CVAT UI界面半自动标注功能处显示的模型名称
type: detector # 功能类型,交互器interactor/检测器detector/跟踪器tracker
framework: pytorch # 框架,onnx/pytorch/openvino/tensorflow
spec: | # 预训练模型的检测类别信息
[
{ "id": 1, "name": "person" },
{ "id": 2, "name": "bicycle" },
...
{ "id":89, "name": "hair_drier" },
{ "id":90, "name": "toothbrush" }
]
spec:
description: RetinaNet R101 from Detectron2 # 模型描述信息
runtime: 'python:3.8' # python版本
handler: main:handler
eventTimeout: 30s
build:
image: cvat/pth.facebookresearch.detectron2.retinanet_r101:{tag} # 镜像名称:镜像版本,根据需求自行更改
baseImage: {docker name}:{tag} # 之前安装的基础镜像
directives: # 建立镜像的命令,类比Dockerfile内容,但目前不支持COPY、ADD等命令,RUN、WORKDIR命令可以
preCopy:
- kind: WORKDIR
value: /opt/nuclio # cvat的默认路径,不需要更改
- kind: RUN
value: pip3 install torch==1.8.1+cpu torchvision==0.9.1+cpu torchaudio==0.8.1 # 安装库文件,已安装则pass
triggers:
myHttpTrigger: # 描述http触发,用于处理http请求,默认不改
NumWorkers: 1
kind: 'http'
workerAvailabilityTimeoutMilliseconds: 10000
attributes:
maxRequestBodySize: 33554432 # 32MB
platform: # 描述模型运行时的重要参数,默认不改
attributes:
restartPolicy:
name: always
maximumRetryCount: 3
mountMode: volume(2)function-gpu.yaml
提供 GPU 支持的配置文件,只需在 function.yaml 的内容上稍作修改即可。
description: RetinaNet R101 from Detectron2 optimized for GPU # 修改描述信息
- kind: RUN
value: pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 # 修改要安装的库文件
NumWorkers: 1 # 修改
# 添加
resources:
limits:
nvidia.com/gpu: 1(3)model_handler.py
模型推理脚本,根据自己的模型推理代码修改。
class ModelHandler:
def __init__(self, weights='/opt/nuclio/yolov5s_bunker.pt', device='cpu', dnn=False):
self.device = select_device(device)
self.model = DetectMultiBackend(weights, device=device, dnn=dnn)
def infer(self, image):
imgsz = (640, 640)
stride, names = self.model.stride, self.model.names
imgsz = check_img_size(imgsz, s=stride)
# Padded resize
img = letterbox(image, imgsz, stride=stride, auto=True)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
im, im0s = img, image
results = []
im = torch.from_numpy(im).to(self.device)
im = im.half() if self.model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = self.model(im, augment=False, visualize=False)
# NMS
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, max_det=50)
im0 = im0s.copy()
if pred[0].size()[0] > 0:
for dett in pred:
dett = torch.unsqueeze(dett[0, :], 0)
box = scale_boxes(im.shape[2:], dett[:, :4], im0.shape).round().cpu()
x1 = int(box[0][0])
y1 = int(box[0][1])
x2 = int(box[0][2])
y2 = int(box[0][3])
conf = dett[0][4]
cls = dett[0][5]
results.append({
"confidence": str(float(conf)),
"label": names[int(cls)],
"points": [x1, y1, x2, y2],
"type": "rectangle",
})
return results(4)main.py
CVAT 接口脚本,通过 init_context(context)、handler(context, event) 两个接口函数完成加载模型,并返回特定格式的模型推理结果的功能[8]。
def init_context(context):
context.logger.info("Init context... 0%")
# 修改模型路径
model_path = "/opt/nuclio/yolov5s_bunker.pt"
# 加载模型,并初始化到context
model = ModelHandler(weights=model_path)
context.user_data.model = model
context.logger.info("Init context...100%")
def handler(context, event):
context.logger.info("Run yolov5s_bunker model")
data = event.body
buf = io.BytesIO(base64.b64decode(data["image"]))
image = Image.open(buf)
image = image.convert("RGB") # to make sure image comes in RGB
image = np.array(image)[:, :, ::-1]
# 调用model_handler.py中的infer接口,完成推理
results = context.user_data.model.infer(image)
return context.Response(body=json.dumps(results), headers={},
content_type='application/json', status_code=200)8.4.3 部署
在 cvat 目录下运行以下命令开始部署
nuctl deploy --project-name cvat
--path "./serverless/pytorch/custom/bunkerdet/nuclio" # 之前创建的模型和文件存放路径
--platform local输出如下信息表示部署成功

可以输入 nuctl get functions 或到nuclio面板里查看模型状态,状态为 ready 就是正常


此时再回到 CVAT 任务界面选择 automatic annotation,就可以看到我们部署的模型,之后就可以开始自动标注了。
8.4.4 报错
如果部署完成后模型状态显示为 unhealthy,或者自动标注时报错

可以输入以下命令查看报错信息[9]
docker logs nuclio-nuclio-
根据报错信息修改代码,注意代码存在于两个地方,一个在 cvat/serverless 路径下,一个在 /opt/nuclio 路径下,如果时模型推理相关的代码出了问题,两处都需要修改,修改完成后重新执行 8.4.3 部署即可。
上述过程全部走通,就可以愉快的开始自动标注了。
四、总结
不得不说 CVAT 的部署是挺麻烦的,不过用起来之后很方便,里面有很多功能目前并没有用到,比如团队协作相关功能,分割标注啥的,所以相关部分也没有介绍,后面用到了再说。
还有一个就是根据自己的需求修改源码,添加功能,这一步本身不复杂,官方文档里说改完之后重构一下镜像就可以,但就是卡在了重构镜像这一步,尝试过 N 多次都是由于网络问题没有成功,以后有机会再搞吧。
CVAT 的更新还是挺频繁的,时隔一年多UI界面有了变化,功能上添加了 yolov8 数据格式支持,不过安装方式上应该没啥区别,如果由于更新导致安装出问题,那还是直接去找官方文档按最新教程来吧。
文章仅供学习记录之用,大佬勿喷。
参考资料
[1] 十个最常用深度学习图像/视频数据标注工具-CSDN博客
[2] 13个最受欢迎的图像标注工具【机器学习】-CSDN博客
[3] ubuntu | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
[4] 解决docker: Error response from daemon:
[5] CVAT安装及图片标注使用详细教程[含踩坑记录]-CSDN博客
[6] 【安装、配置、汉化】CVAT: 团队协作与自动标注的图像标注工具_cvat汉化-CSDN博客
[7] Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.16.2 documentation
[8] CVAT半自动标注:如何添加自己的预训练模型 - 作业部落 Cmd Markdown 编辑阅读器
[9] Deploy a model with nuclio successful, but status unhealthy · Issue #6790 · cvat-ai/cvat · GitHub